 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Lightweight Hybrid Graph Convolutional Neural Network -- CNN Scheme for Scene Classification using Object Detection Inference
Jul 19, 2024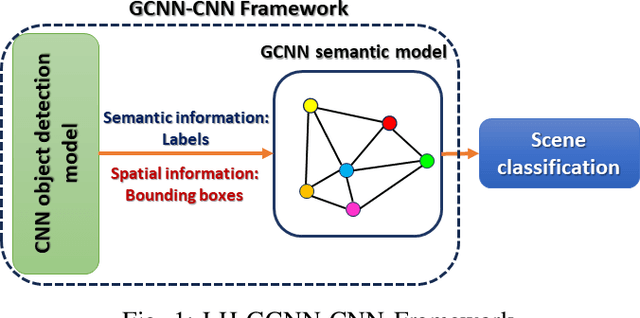
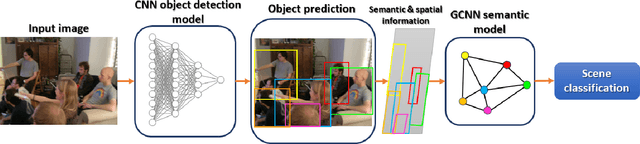
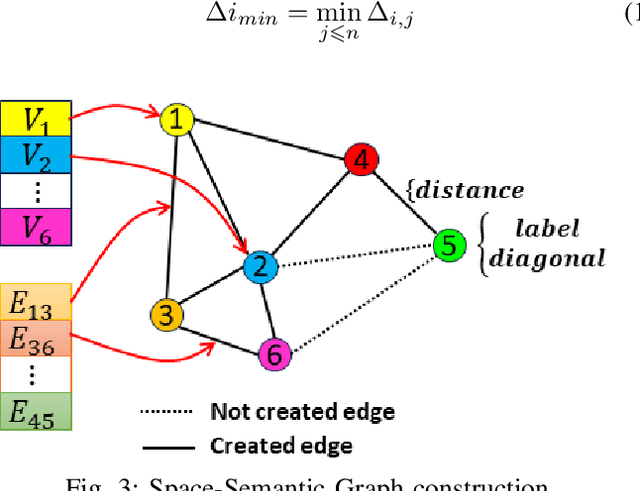
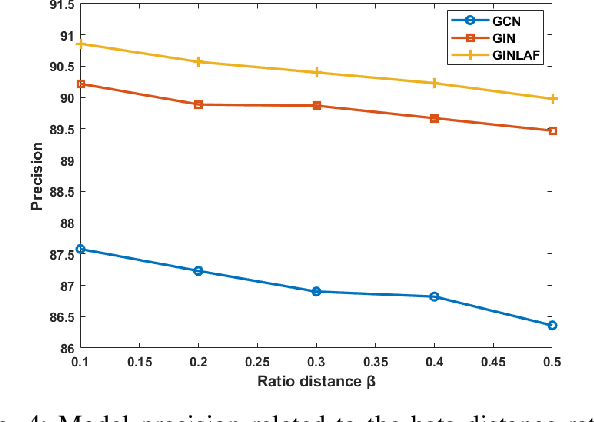
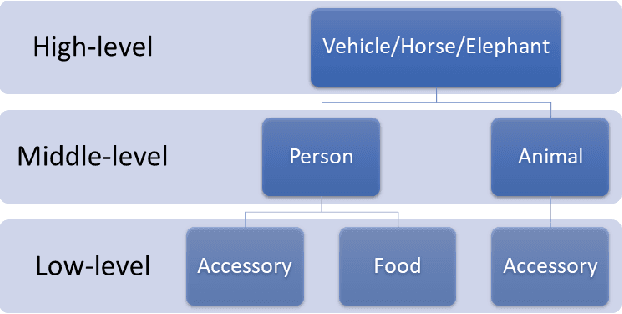
Scene understanding plays an important role in several high-level computer vision applications, such as autonomous vehicles, intelligent video surveillance, or robotics. However, too few solutions have been proposed for indoor/outdoor scene classification to ensure scene context adaptability for computer vision frameworks. We propose the first Lightweight Hybrid Graph Convolutional Neural Network (LH-GCNN)-CNN framework as an add-on to object detection models. The proposed approach uses the output of the CNN object detection model to predict the observed scene type by generating a coherent GCNN representing the semantic and geometric content of the observed scene. This new method, applied to natural scenes, achieves an efficiency of over 90\% for scene classification in a COCO-derived dataset containing a large number of different scenes, while requiring fewer parameters than traditional CNN methods. For the benefit of the scientific community, we will make the source code publicly available: https://github.com/Aymanbegh/Hybrid-GCNN-CNN.
CD-COCO: A Versatile Complex Distorted COCO Database for Scene-Context-Aware Computer Vision
Nov 12, 2023

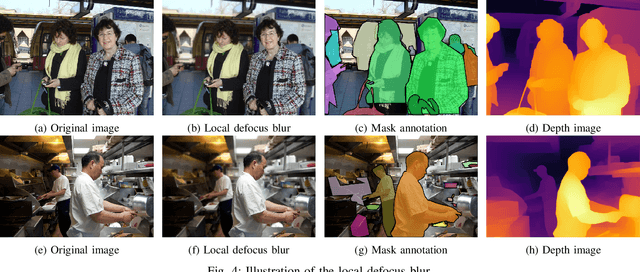
The recent development of deep learning methods applied to vision has enabled their increasing integration into real-world applications to perform complex Computer Vision (CV) tasks. However, image acquisition conditions have a major impact on the performance of high-level image processing. A possible solution to overcome these limitations is to artificially augment the training databases or to design deep learning models that are robust to signal distortions. We opt here for the first solution by enriching the database with complex and realistic distortions which were ignored until now in the existing databases. To this end, we built a new versatile database derived from the well-known MS-COCO database to which we applied local and global photo-realistic distortions. These new local distortions are generated by considering the scene context of the images that guarantees a high level of photo-realism. Distortions are generated by exploiting the depth information of the objects in the scene as well as their semantics. This guarantees a high level of photo-realism and allows to explore real scenarios ignored in conventional databases dedicated to various CV applications. Our versatile database offers an efficient solution to improve the robustness of various CV tasks such as Object Detection (OD), scene segmentation, and distortion-type classification methods. The image database, scene classification index, and distortion generation codes are publicly available \footnote{\url{https://github.com/Aymanbegh/CD-COCO}}
Benchmarking performance of object detection under image distortions in an uncontrolled environment
Oct 28, 2022The robustness of object detection algorithms plays a prominent role in real-world applications, especially in uncontrolled environments due to distortions during image acquisition. It has been proven that the performance of object detection methods suffers from in-capture distortions. In this study, we present a performance evaluation framework for the state-of-the-art object detection methods using a dedicated dataset containing images with various distortions at different levels of severity. Furthermore, we propose an original strategy of image distortion generation applied to the MS-COCO dataset that combines some local and global distortions to reach much better performances. We have shown that training using the proposed dataset improves the robustness of object detection by 31.5\%. Finally, we provide a custom dataset including natural images distorted from MS-COCO to perform a more reliable evaluation of the robustness against common distortions. The database and the generation source codes of the different distortions are made publicly available
D2SLAM: Semantic visual SLAM based on the influence of Depth for Dynamic environments
Oct 16, 2022
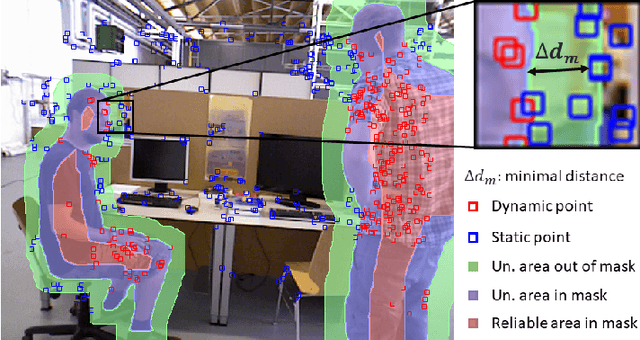


Taking into account the dynamics of the scene is the most effective solution to obtain an accurate perception of unknown environments within the framework of a real autonomous robotic application. Many works have attempted to address the non-rigid scene assumption by taking advantage of deep learning advancements. Most new methods combine geometric and semantic approaches to determine dynamic elements that lack generalization and scene awareness. We propose a novel approach that overcomes the limitations of these methods by using scene depth information that refines the accuracy of estimates from geometric and semantic modules. In addition, the depth information is used to determine an area of influence of dynamic objects through our Objects Interaction module that estimates the state of both non-matched keypoints and out of segmented region keypoints. The obtained results demonstrate the efficacy of the proposed method in providing accurate localization and mapping in dynamic environments.