 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll at Once Network Quantization via Collaborative Knowledge Transfer
Paper and Code
Mar 02, 2021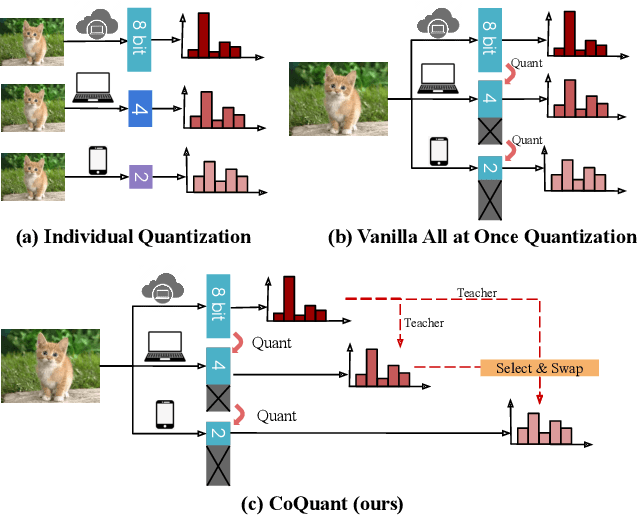
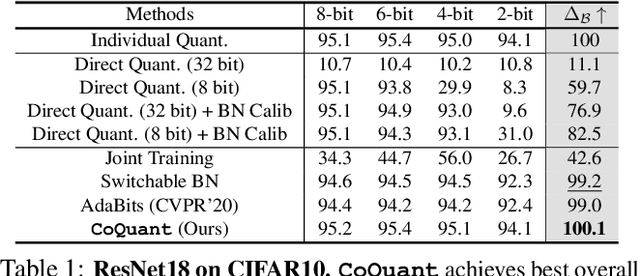
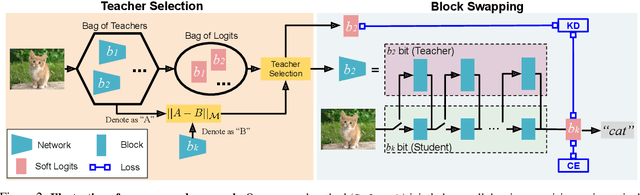
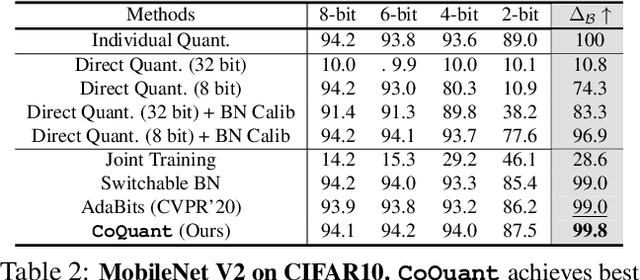
Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks on edge devices. While existing approaches offer impressive results on common benchmark datasets, they generally repeat the quantization process and retrain the low-precision network from scratch, leading to different networks tailored for different resource constraints. This limits scalable deployment of deep networks in many real-world applications, where in practice dynamic changes in bit-width are often desired. All at Once quantization addresses this problem, by flexibly adjusting the bit-width of a single deep network during inference, without requiring re-training or additional memory to store separate models, for instant adaptation in different scenarios. In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network. Specifically, we propose an adaptive selection strategy to choose a high-precision \enquote{teacher} for transferring knowledge to the low-precision student while jointly optimizing the model with all bit-widths. Furthermore, to effectively transfer knowledge, we develop a dynamic block swapping method by randomly replacing the blocks in the lower-precision student network with the corresponding blocks in the higher-precision teacher network. Extensive experiments on several challenging and diverse datasets for both image and video classification well demonstrate the efficacy of our proposed approach over state-of-the-art methods.