 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization
Paper and Code


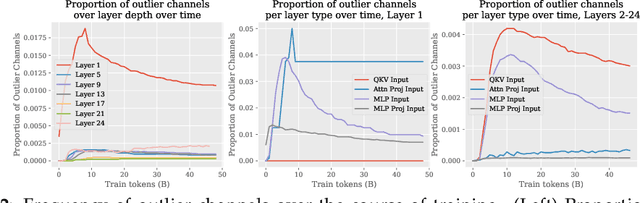

We consider the problem of accurate quantization for language models, where both the weights and activations are uniformly quantized to 4 bits per parameter, the lowest bitwidth format natively supported by GPU hardware. In this context, the key challenge is activation quantization: it is known that language models contain outlier channels whose values on average are orders of magnitude higher than than other channels, which prevents accurate low-bitwidth quantization with known techniques. We systematically study this phenomena and find that these outlier channels emerge early in training, and that they occur more frequently in layers with residual streams. We then propose a simple strategy which regularizes a layer's inputs via quantization-aware training (QAT) and its outputs via activation kurtosis regularization. We show that regularizing both the inputs and outputs is crucial for preventing a model's "migrating" the difficulty in input quantization to the weights, which makes post-training quantization (PTQ) of weights more difficult. When combined with weight PTQ, we show that our approach can obtain a W4A4 model that performs competitively to the standard-precision W16A16 baseline.