 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPLOYO: A Pulmonary Nodule Detection Model with Multi-Scale Feature Fusion and Nonlinear Feature Learning
Mar 13, 2025

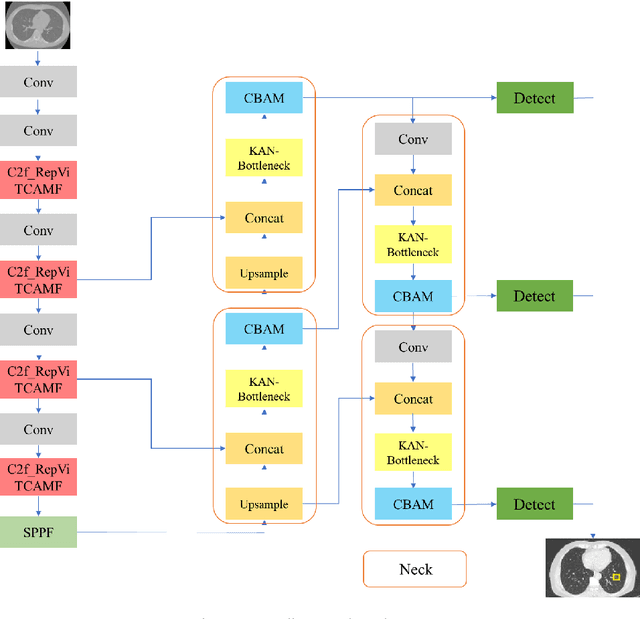

The integration of Internet of Things (IoT) technology in pulmonary nodule detection significantly enhances the intelligence and real-time capabilities of the detection system. Currently, lung nodule detection primarily focuses on the identification of solid nodules, but different types of lung nodules correspond to various forms of lung cancer. Multi-type detection contributes to improving the overall lung cancer detection rate and enhancing the cure rate. To achieve high sensitivity in nodule detection, targeted improvements were made to the YOLOv8 model. Firstly, the C2f\_RepViTCAMF module was introduced to augment the C2f module in the backbone, thereby enhancing detection accuracy for small lung nodules and achieving a lightweight model design. Secondly, the MSCAF module was incorporated to reconstruct the feature fusion section of the model, improving detection accuracy for lung nodules of varying scales. Furthermore, the KAN network was integrated into the model. By leveraging the KAN network's powerful nonlinear feature learning capability, detection accuracy for small lung nodules was further improved, and the model's generalization ability was enhanced. Tests conducted on the LUNA16 dataset demonstrate that the improved model outperforms the original model as well as other mainstream models such as YOLOv9 and RT-DETR across various evaluation metrics.
Optimized CNNs for Rapid 3D Point Cloud Object Recognition
Dec 03, 2024
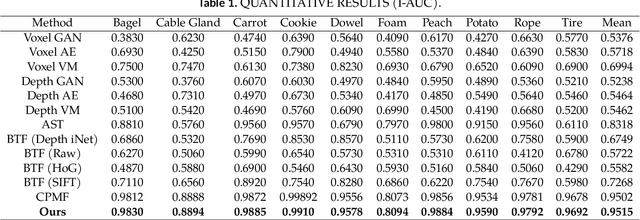

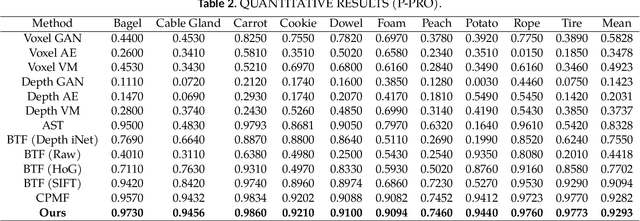
This study introduces a method for efficiently detecting objects within 3D point clouds using convolutional neural networks (CNNs). Our approach adopts a unique feature-centric voting mechanism to construct convolutional layers that capitalize on the typical sparsity observed in input data. We explore the trade-off between accuracy and speed across diverse network architectures and advocate for integrating an $\mathcal{L}_1$ penalty on filter activations to augment sparsity within intermediate layers. This research pioneers the proposal of sparse convolutional layers combined with $\mathcal{L}_1$ regularization to effectively handle large-scale 3D data processing. Our method's efficacy is demonstrated on the MVTec 3D-AD object detection benchmark. The Vote3Deep models, with just three layers, outperform the previous state-of-the-art in both laser-only approaches and combined laser-vision methods. Additionally, they maintain competitive processing speeds. This underscores our approach's capability to substantially enhance detection performance while ensuring computational efficiency suitable for real-time applications.
Data-Driven Spatiotemporal Feature Representation and Mining in Multidimensional Time Series
Sep 22, 2024
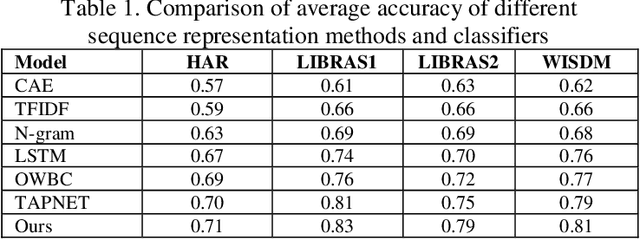

This paper explores a new method for time series data analysis, aiming to overcome the limitations of traditional mining techniques when dealing with multidimensional time series data. Time series data are extensively utilized in diverse fields, including backend services for monitoring and optimizing IT infrastructure, medical diagnosis through continuous patient monitoring and health trend analysis, and internet business for tracking user behavior and forecasting sales. However, since the effective information in time series data is often hidden in sequence fragments, the uncertainty of their length, quantity, and morphological variables brings challenges to mining. To this end, this paper proposes a new spatiotemporal feature representation method, which converts multidimensional time series (MTS) into one-dimensional event sequences by transforming spatially varying events, and uses a series of event symbols to represent the spatial structural information of multidimensional coupling in the sequence, which has good interpretability. Then, this paper introduces a variable-length tuple mining method to extract non-redundant key event subsequences in event sequences as spatiotemporal structural features of motion sequences. This method is an unsupervised method that does not rely on large-scale training samples and defines a new model for representing the spatiotemporal structural features of multidimensional time series. The superior performance of the STEM model is verified by pattern classification experiments on a variety of motion sequences. The research results of this paper provide an important theoretical basis and technical support for understanding and predicting human behavior patterns, and have far-reaching practical application value.