 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Cloud-Grade SLOs for Local Mixture-of-Experts Inference through CPU-GPU Hybrid Design
Jun 09, 2026Local deployment of large Mixture-of-Experts (MoE) models falls short of the service quality achieved in cloud-scale environments, even under low-concurrency workloads. We identify four key gaps in local MoE inference: reliance on capacity-reduced models (quantized, distilled, rerouted), inability to meet 30-second TTFT for long prefills (more than 12K), sub-baseline decode throughput (under 20 tokens/s), and poor concurrency under mixed prefill-decode and batched decode workloads. We present a CPU-GPU hybrid system that achieves cloud-level SLOs on dual-socket commodity CPUs and consumer GPUs by (1) stream-loading prefill (SLP), boosting prefill throughput to 1,200 tokens/s and enabling 32K prompts within 30 seconds; (2) distributed SLP (DSLP) with SmallEP expert parallelism, reaching 1,800 tokens/s and 45K prompts in 30 seconds on two RTX 5090s; (3) intra-node prefill-decode disaggregation with zero-copy shared weights and a dual-batch attention-MoE overlap scheme, sustaining concurrency with under 15 percent latency increase and 50 percent throughput gains; (4) an AVX-512-optimized FP8 GEMV kernel, enabling native CPU FP8 inference while delivering 4-5x lower CPU latency; and (5) fine-grained CPU parallelism that attains 28 tokens/s on INT4 DeepSeek-V3 and 21.5 tokens/s on intact FP8 V3. Evaluations show our system delivers cloud-level QoS for flagship MoE models on consumer CPU-GPU platforms, reshaping local deployment with intact, original-precision inference and enabling high-quality, cost-effective access without datacenter infrastructure.
Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
May 26, 2026Large language models (LLMs) have shown strong empirical gains as self-evolving agents for CUDA kernel generation, driven by feedback-conditioned planning across generations. However, how planning decisions attribute and combine heterogeneous feedback signals remains opaque. Standard end-to-end ablations fail to resolve this question, as iterative planning amplifies early perturbations and conflates feedback effects with trajectory-dependent drift. We introduce \texttt{CUDAnalyst}, a unified analysis layer for controlled, generation-level attribution of planning decisions to feedback components via trajectory freezing and selective feedback injection. \texttt{CUDAnalyst} enables stable generation-level evaluation and principled coalitional-style attribution of feedback effects and interactions. Our results show that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones. These trends hold across reference backbones, representative workloads, and reference induction regimes, indicating that the identified feedback-to-plan structure is robust within the controlled axes studied.
BrainFuse: a unified infrastructure integrating realistic biological modeling and core AI methodology
Jan 29, 2026Neuroscience and artificial intelligence represent distinct yet complementary pathways to general intelligence. However, amid the ongoing boom in AI research and applications, the translational synergy between these two fields has grown increasingly elusive-hampered by a widening infrastructural incompatibility: modern AI frameworks lack native support for biophysical realism, while neural simulation tools are poorly suited for gradient-based optimization and neuromorphic hardware deployment. To bridge this gap, we introduce BrainFuse, a unified infrastructure that provides comprehensive support for biophysical neural simulation and gradient-based learning. By addressing algorithmic, computational, and deployment challenges, BrainFuse exhibits three core capabilities: (1) algorithmic integration of detailed neuronal dynamics into a differentiable learning framework; (2) system-level optimization that accelerates customizable ion-channel dynamics by up to 3,000x on GPUs; and (3) scalable computation with highly compatible pipelines for neuromorphic hardware deployment. We demonstrate this full-stack design through both AI and neuroscience tasks, from foundational neuron simulation and functional cylinder modeling to real-world deployment and application scenarios. For neuroscience, BrainFuse supports multiscale biological modeling, enabling the deployment of approximately 38,000 Hodgkin-Huxley neurons with 100 million synapses on a single neuromorphic chip while consuming as low as 1.98 W. For AI, BrainFuse facilitates the synergistic application of realistic biological neuron models, demonstrating enhanced robustness to input noise and improved temporal processing endowed by complex HH dynamics. BrainFuse therefore serves as a foundational engine to facilitate cross-disciplinary research and accelerate the development of next-generation bio-inspired intelligent systems.
Pipelining Kruskal's: A Neuromorphic Approach for Minimum Spanning Tree
May 19, 2025Neuromorphic computing, characterized by its event-driven computation and massive parallelism, is particularly effective for handling data-intensive tasks in low-power environments, such as computing the minimum spanning tree (MST) for large-scale graphs. The introduction of dynamic synaptic modifications provides new design opportunities for neuromorphic algorithms. Building on this foundation, we propose an SNN-based union-sort routine and a pipelined version of Kruskal's algorithm for MST computation. The event-driven nature of our method allows for the concurrent execution of two completely decoupled stages: neuromorphic sorting and union-find. Our approach demonstrates superior performance compared to state-of-the-art Prim 's-based methods on large-scale graphs from the DIMACS10 dataset, achieving speedups by 269.67x to 1283.80x, with a median speedup of 540.76x. We further evaluate the pipelined implementation against two serial variants of Kruskal's algorithm, which rely on neuromorphic sorting and neuromorphic radix sort, showing significant performance advantages in most scenarios.
AIPerf: Automated machine learning as an AI-HPC benchmark
Aug 26, 2020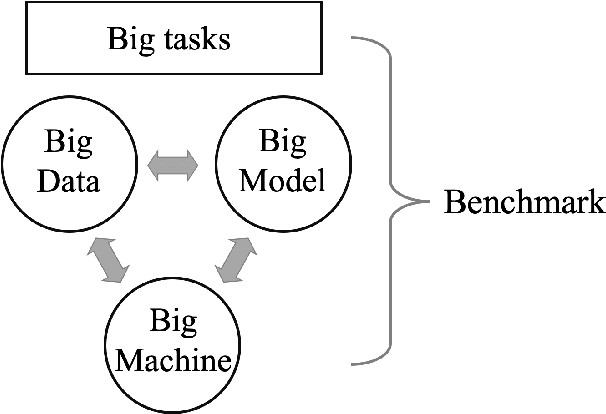
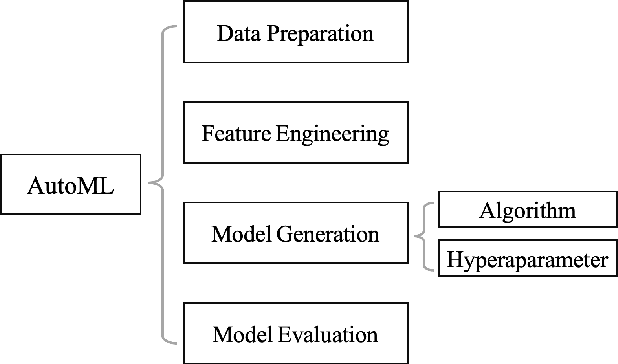

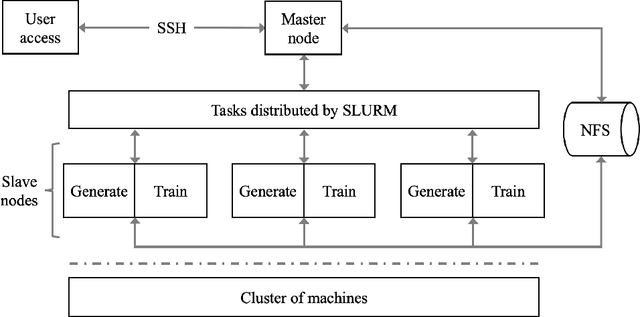
The plethora of complex artificial intelligence (AI) algorithms and available high performance computing (HPC) power stimulates the convergence of AI and HPC. The expeditious development of AI components, in both hardware and software domain, increases the system heterogeneity, which prompts the challenge on fair and comprehensive benchmarking. Existing HPC and AI benchmarks fail to cover the variety of heterogeneous systems while providing a simple quantitative measurement to reflect the overall performance of large clusters for AI tasks. To address the challenges, we specify the requirements of an AI-HPC considering the future scenarios and propose an end-to-end benchmark suite utilizing automated machine learning (AutoML) as a representative AI application. The extremely high computational cost and high scalability make AutoML a desired workload candidate for AI-HPC benchmark. We implement the algorithms in a highly efficient and parallel way to ensure automatic adaption on various systems regarding AI accelerator's memory and quantity. The benchmark is particularly customizable on back-end training framework and hyperparameters so as to achieve optimal performance on diverse systems. The major metric to quantify the machine performance is floating-point operations per second (FLOPS), which is measured in a systematic and analytical approach. We also provide a regulated score as a complementary result to reflect hardware and software co-performance. We verify the benchmark's linear scalability on different scales of nodes up to 16 equipped with 128 GPUs and evaluate the stability as well as reproducibility at discrete timestamps. The source code, specifications, and detailed procedures are publicly accessible on GitHub: https://github.com/AI-HPC-Research-Team/AIPerf.
Brain-inspired global-local hybrid learning towards human-like intelligence
Jun 05, 2020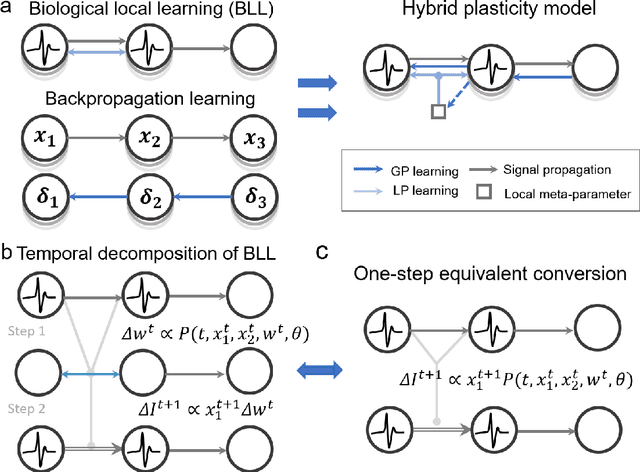
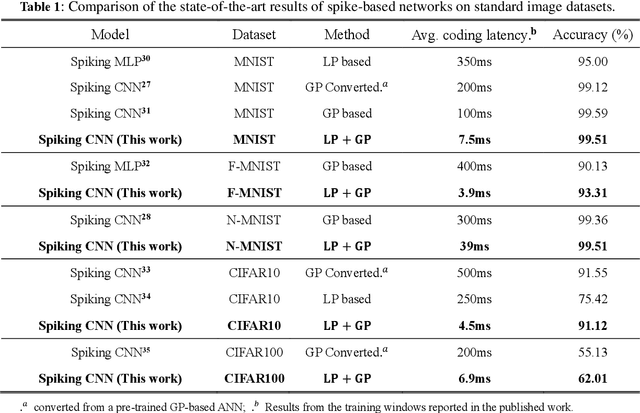
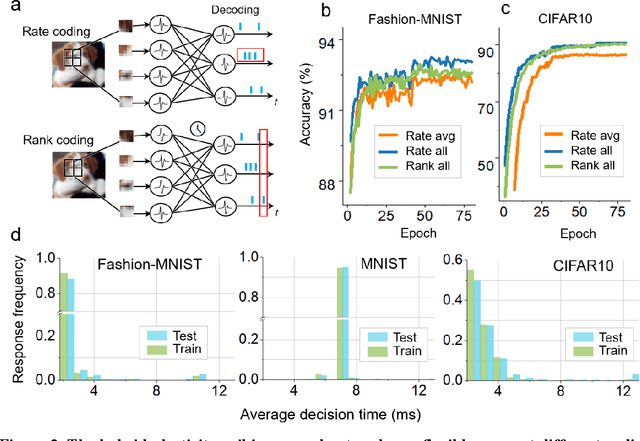
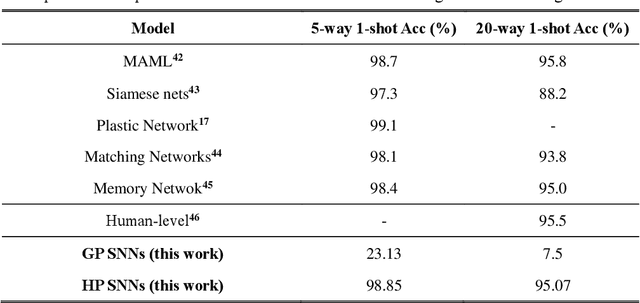
The combination of neuroscience-oriented and computer-science-oriented approaches is the most promising method to develop artificial general intelligence (AGI) that can learn general tasks similar to humans. Currently, two main routes of learning exist, including neuroscience-inspired methods, represented by local synaptic plasticity, and machine-learning methods, represented by backpropagation. Both have advantages and complement each other, but neither can solve all learning problems well. Integrating these two methods into one network may provide better learning abilities for general tasks. Here, we report a hybrid spiking neural network model that integrates the two approaches by introducing a meta-local module and a two-phase causality modelling method. The model can not only optimize local plasticity rules, but also receive top-down supervision information. In addition to flexibly supporting multiple spike-based coding schemes, we demonstrate that this model facilitates learning of many general tasks, including fault-tolerance learning, few-shot learning and multiple-task learning, and show its efficiency on the Tianjic neuromorphic platform. This work provides a new route for brain-inspired computing and facilitates AGI development.
FPSA: A Full System Stack Solution for Reconfigurable ReRAM-based NN Accelerator Architecture
Jan 28, 2019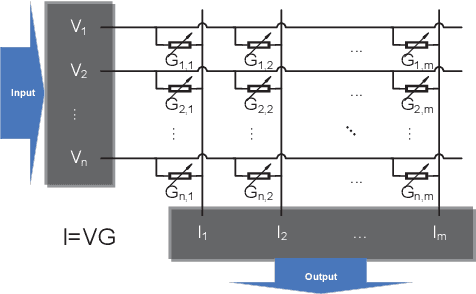
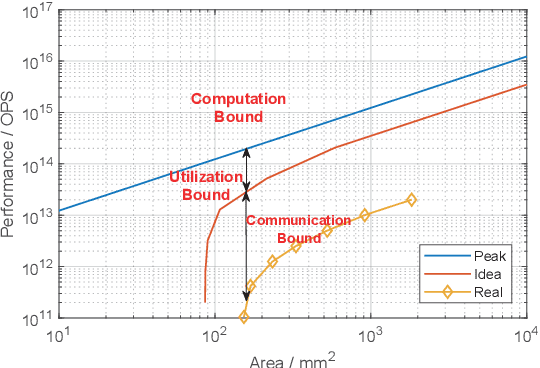
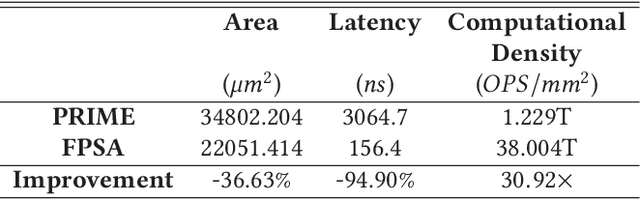
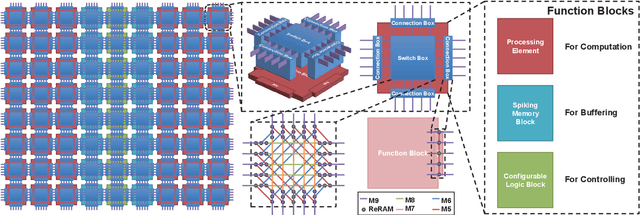
Neural Network (NN) accelerators with emerging ReRAM (resistive random access memory) technologies have been investigated as one of the promising solutions to address the \textit{memory wall} challenge, due to the unique capability of \textit{processing-in-memory} within ReRAM-crossbar-based processing elements (PEs). However, the high efficiency and high density advantages of ReRAM have not been fully utilized due to the huge communication demands among PEs and the overhead of peripheral circuits. In this paper, we propose a full system stack solution, composed of a reconfigurable architecture design, Field Programmable Synapse Array (FPSA) and its software system including neural synthesizer, temporal-to-spatial mapper, and placement & routing. We highly leverage the software system to make the hardware design compact and efficient. To satisfy the high-performance communication demand, we optimize it with a reconfigurable routing architecture and the placement & routing tool. To improve the computational density, we greatly simplify the PE circuit with the spiking schema and then adopt neural synthesizer to enable the high density computation-resources to support different kinds of NN operations. In addition, we provide spiking memory blocks (SMBs) and configurable logic blocks (CLBs) in hardware and leverage the temporal-to-spatial mapper to utilize them to balance the storage and computation requirements of NN. Owing to the end-to-end software system, we can efficiently deploy existing deep neural networks to FPSA. Evaluations show that, compared to one of state-of-the-art ReRAM-based NN accelerators, PRIME, the computational density of FPSA improves by 31x; for representative NNs, its inference performance can achieve up to 1000x speedup.
Programmable Neural Network Trojan for Pre-Trained Feature Extractor
Jan 23, 2019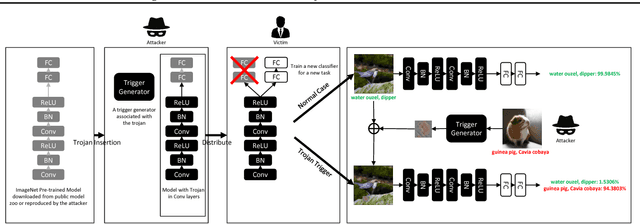
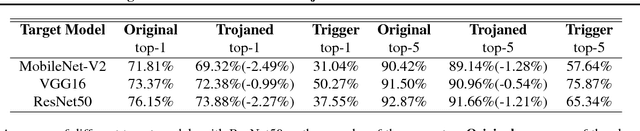
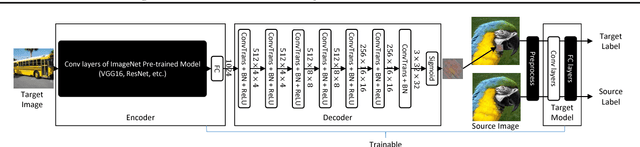
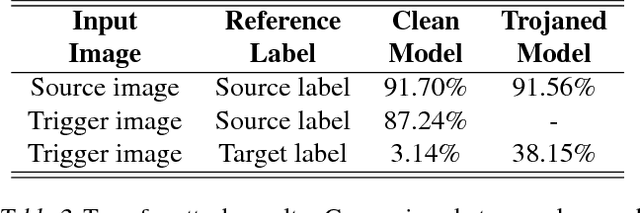
Neural network (NN) trojaning attack is an emerging and important attack model that can broadly damage the system deployed with NN models. Existing studies have explored the outsourced training attack scenario and transfer learning attack scenario in some small datasets for specific domains, with limited numbers of fixed target classes. In this paper, we propose a more powerful trojaning attack method for both outsourced training attack and transfer learning attack, which outperforms existing studies in the capability, generality, and stealthiness. First, The attack is programmable that the malicious misclassification target is not fixed and can be generated on demand even after the victim's deployment. Second, our trojan attack is not limited in a small domain; one trojaned model on a large-scale dataset can affect applications of different domains that reuse its general features. Thirdly, our trojan design is hard to be detected or eliminated even if the victims fine-tune the whole model.