 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules
Dec 07, 2021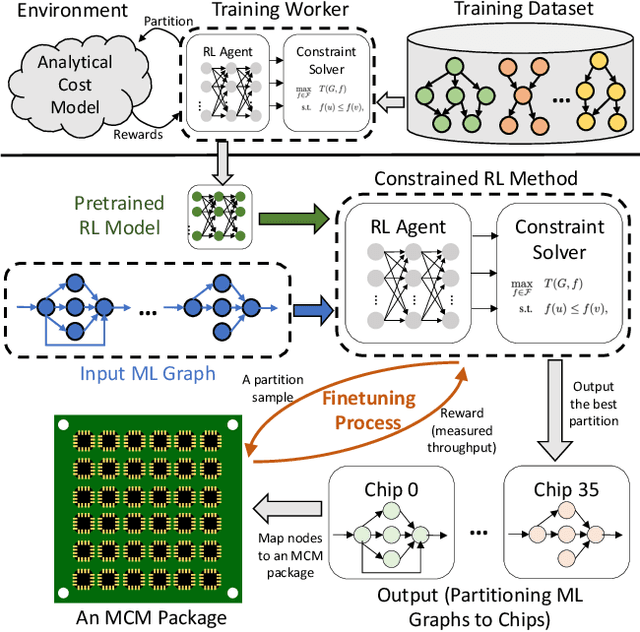
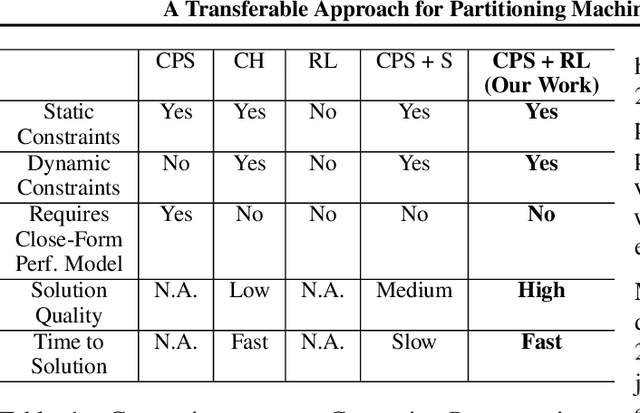
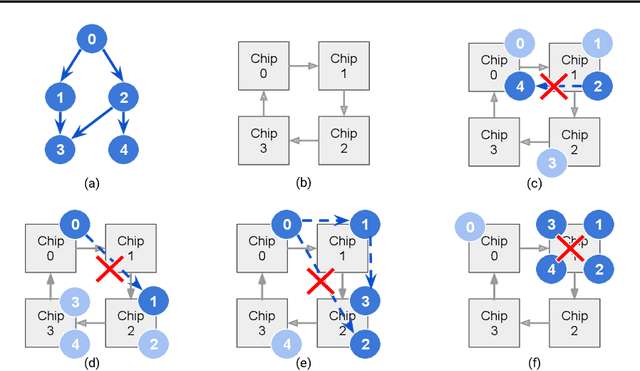

Multi-Chip-Modules (MCMs) reduce the design and fabrication cost of machine learning (ML) accelerators while delivering performance and energy efficiency on par with a monolithic large chip. However, ML compilers targeting MCMs need to solve complex optimization problems optimally and efficiently to achieve this high performance. One such problem is the multi-chip partitioning problem where compilers determine the optimal partitioning and placement of operations in tensor computation graphs on chiplets in MCMs. Partitioning ML graphs for MCMs is particularly hard as the search space grows exponentially with the number of chiplets available and the number of nodes in the neural network. Furthermore, the constraints imposed by the underlying hardware produce a search space where valid solutions are extremely sparse. In this paper, we present a strategy using a deep reinforcement learning (RL) framework to emit a possibly invalid candidate partition that is then corrected by a constraint solver. Using the constraint solver ensures that RL encounters valid solutions in the sparse space frequently enough to converge with fewer samples as compared to non-learned strategies. The architectural choices we make for the policy network allow us to generalize across different ML graphs. Our evaluation of a production-scale model, BERT, on real hardware reveals that the partitioning generated using RL policy achieves 6.11% and 5.85% higher throughput than random search and simulated annealing. In addition, fine-tuning the pre-trained RL policy reduces the search time from 3 hours to only 9 minutes, while achieving the same throughput as training RL policy from scratch.