 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Guarantees against Data Poisoning Using Self-Expansion and Compatibility
May 08, 2021
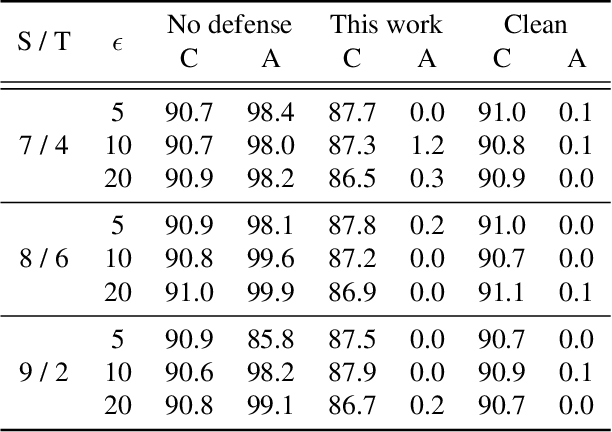

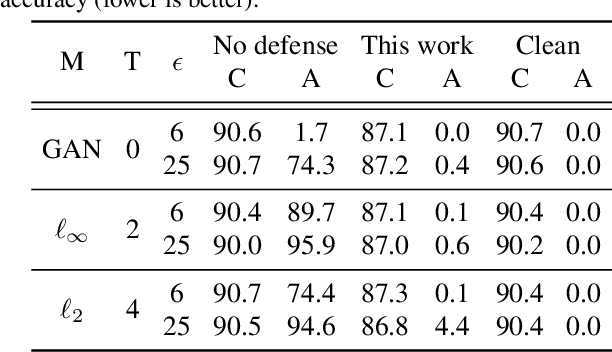
A recent line of work has shown that deep networks are highly susceptible to backdoor data poisoning attacks. Specifically, by injecting a small amount of malicious data into the training distribution, an adversary gains the ability to control the model's behavior during inference. In this work, we propose an iterative training procedure for removing poisoned data from the training set. Our approach consists of two steps. We first train an ensemble of weak learners to automatically discover distinct subpopulations in the training set. We then leverage a boosting framework to recover the clean data. Empirically, our method successfully defends against several state-of-the-art backdoor attacks, including both clean and dirty label attacks. We also present results from an independent third-party evaluation including a recent \textit{adaptive} poisoning adversary. The results indicate our approach is competitive with existing defenses against backdoor attacks on deep neural networks, and significantly outperforms the state-of-the-art in several scenarios.