 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Textual Embedding against Word-level Adversarial Attacks
Paper and Code
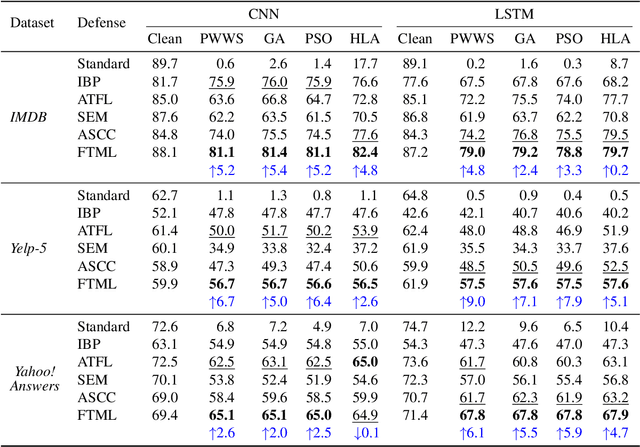
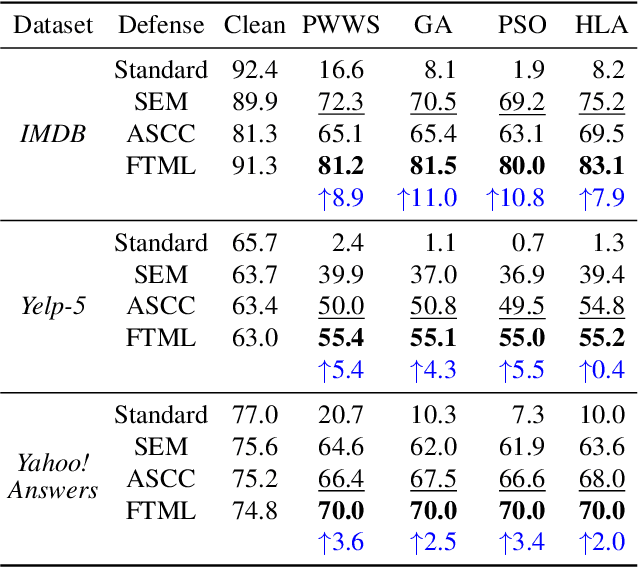
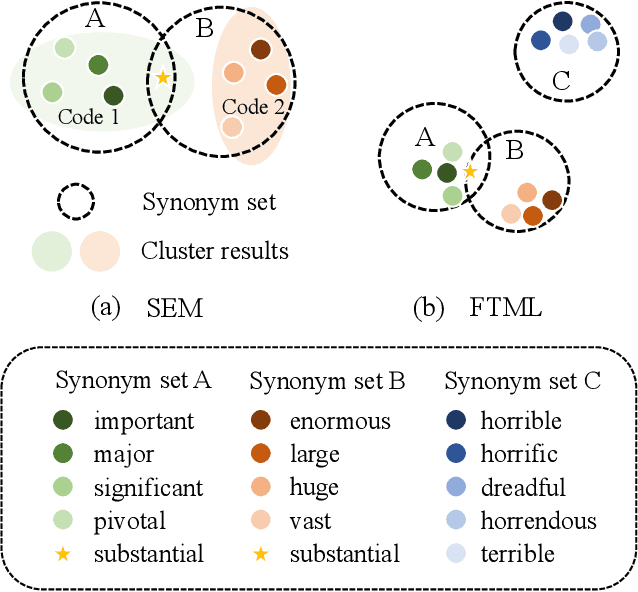
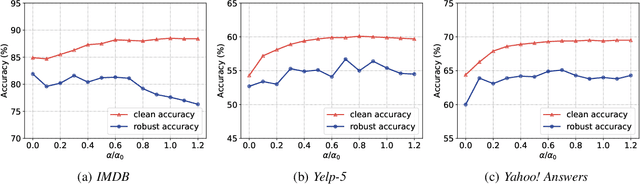
We attribute the vulnerability of natural language processing models to the fact that similar inputs are converted to dissimilar representations in the embedding space, leading to inconsistent outputs, and propose a novel robust training method, termed Fast Triplet Metric Learning (FTML). Specifically, we argue that the original sample should have similar representation with its adversarial counterparts and distinguish its representation from other samples for better robustness. To this end, we adopt the triplet metric learning into the standard training to pull the words closer to their positive samples (i.e., synonyms) and push away their negative samples (i.e., non-synonyms) in the embedding space. Extensive experiments demonstrate that FTML can significantly promote the model robustness against various advanced adversarial attacks while keeping competitive classification accuracy on original samples. Besides, our method is efficient as it only needs to adjust the embedding and introduces very little overhead on the standard training. Our work shows the great potential of improving the textual robustness through robust word embedding.