 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Reward-Punishment Learning from Fixed-Channel Perceptual Event Streams without Environment Rewards
Jun 17, 2026We study online reward-punishment learning when the environment provides no scalar reward or evaluative label. At each step the agent receives only a fixed-channel perceptual packet, and quantities such as pain, energy, contact, damage, or cognitive error are treated as perceptual dimensions whose valence must be inferred from transition consequences. OHIRL separates four roles: M_psi learns next-packet prediction, D_omega models residual dynamics, C_eta is a fixed internal post-transition trajectory evaluator, and B_xi learns to use the resulting value evidence for later policy updates and action scoring. C_eta uses a recovery-positive and persistence/growth-negative residual-regulation orientation; a coefficient-origin audit shows that equal-unit, raw-equal, and random monotone variants preserve more than 92% of the released top-action rankings, while sign inversion preserves 0%. The reward-free protocol exposes observation transitions while withholding environment rewards, delayed external evaluators, success labels, and action-goodness labels. A conditional error decomposition separates B_xi evidence-estimation error from residual policy-optimization error. In a 2x2-XOR packet task, medicine and chili acquire opposite value under visual XOR contexts, and the same pain or spice increase can be positive or negative depending on consequence structure; B_xi reaches 0.952 balanced reward-sign accuracy. In a full online-interleaved audit, M_psi reaches holdout R2=0.907, B_xi reaches 0.940 sign accuracy, and the policy reaches 0.979 optimal-action accuracy, while immediate packet scores, prediction-error rewards, shuffled targets, zero reward, and error-reduction controls collapse. Hidden-reward CartPole and Taxi controls, public-context no-leakage audits, and module-role ablations further test information boundaries and component necessity.
GrapNet: A Programmable Dynamic-Architecture Neural Graph Substrate
Jun 17, 2026Programmability is a missing first-class interface in fixed-tensor neural networks: editing a relation, freezing a subgraph, auditing a local function, or changing the execution backend should be an operation on the neural program rather than ad-hoc parameter surgery. GrapNet studies this graph-as-network setting. The graph is the architecture and executable program, not an input data graph. Each compute node owns its next-layer child references and a trainable allocation vector aligned with those references; deleting a relation physically removes both the child reference and the corresponding allocation coordinate. Structural rules and execution policies live outside the node core, so the same child-owned graph can be grown, frozen, structurally edited, grouped into trainable family blocks, routed by attention over active relations, or lowered to dense snapshots after topology stabilizes. GrapNet composes with conventional modules through a vector-valued parent interface: dense layers, CNN encoders, ResNet feature extractors, attention blocks, and transformer representations can all feed one sensory GrapNode per coordinate. The evaluation is organized as a programmability stress suite rather than as a new replay benchmark. In a matched ten-seed Split Fashion-MNIST study, a plastic GrapNet+ER head reaches 63.16 percent seen-class accuracy versus 51.08 percent for a parameter-larger dense MLP+ER under the same seen-class loss and replay memory, with paired delta 12.08 points and p=1.3e-5. On Split CIFAR-10 with a frozen ImageNet ResNet-18 encoder, the same substrate improves the online head over MLP-256 by 3.81 points, with p=0.0026. These results support GrapNet as an editable neural graph substrate whose core value is structural programmability with faithful execution views.
ScribbleDose: Scribble-Guided Dose Prediction in Radiotherapy
May 12, 2026Anatomical structure masks are widely adopted in radiotherapy dose prediction, as they provide explicit geometric constraints that facilitate structure-dose coupling. However, conventional manual delineation of these masks requires precise annotation of structure boundaries relevant to radiotherapy, which is time-consuming and labor-intensive. To address these limitations, we propose a scribble-guided dose prediction framework that relies solely on anatomical structures annotated with sparse scribbles. Specifically, we design a Scribble Completion Module (SCM) to generate dense anatomical masks by propagating sparse scribble labels to semantically similar voxels. During the propagation process, a supervoxel-based regularization is introduced to preserve geometric boundary consistency to ensure anatomical plausibility. Furthermore, we propose a Structure-Guided Dose Generation Module (SGDGM) to strengthen the correspondence between sparse structural cues and dose distribution. The completed dense masks derived from scribbles serve as structural guidance to condition dose prediction, forming a scribble-mask-dose learning pipeline under sparse annotation. Experiments on the GDP-HMM dataset demonstrate that ScribbleDose achieves competitive dose prediction performance using only sparse structural annotations. The source code and reannotated scribble annotations are publicly available at https://github.com/iCherishxixixi/ScribbleDose.
Generative Drifting for Conditional Medical Image Generation
Apr 21, 2026Conditional medical image generation plays an important role in many clinically relevant imaging tasks. However, existing methods still face a fundamental challenge in balancing inference efficiency, patient-specific fidelity, and distribution-level plausibility, particularly in high-dimensional 3D medical imaging. In this work, we propose GDM, a generative drifting framework that reformulates deterministic medical image prediction as a multi-objective learning problem to jointly promote distribution-level plausibility and patient-specific fidelity while retaining one-step inference. GDM extends drifting to 3D medical imaging through an attractive-repulsive drift that minimizes the discrepancy between the generator pushforward and the target distribution. To enable stable drifting-based learning in 3D volumetric data, GDM constructs a multi-level feature bank from a medical foundation encoder to support reliable affinity estimation and drifting field computation across complementary global, local, and spatial representations. In addition, a gradient coordination strategy in the shared output space improves optimization balance under competing distribution-level and fidelity-oriented objectives. We evaluate the proposed framework on two representative tasks, MRI-to-CT synthesis and sparse-view CT reconstruction. Experimental results show that GDM consistently outperforms a wide range of baselines, including GAN-based, flow-matching-based, and SDE-based generative models, as well as supervised regression methods, while improving the balance among anatomical fidelity, quantitative reliability, perceptual realism, and inference efficiency. These findings suggest that GDM provides a practical and effective framework for conditional 3D medical image generation.
Two-and-a-half Order Score-based Model for Solving 3D Ill-posed Inverse Problems
Aug 17, 2023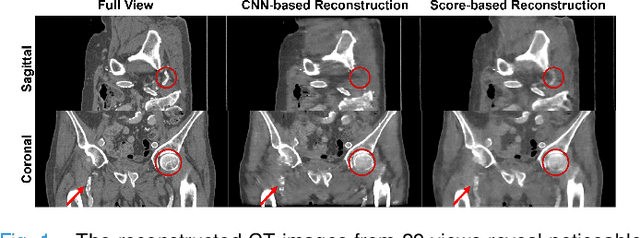

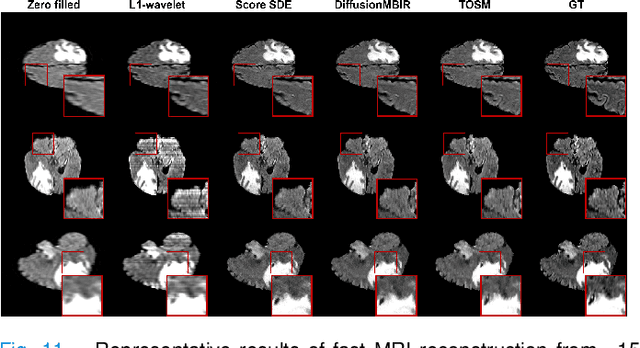

Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) are crucial technologies in the field of medical imaging. Score-based models have proven to be effective in addressing different inverse problems encountered in CT and MRI, such as sparse-view CT and fast MRI reconstruction. However, these models face challenges in achieving accurate three dimensional (3D) volumetric reconstruction. The existing score-based models primarily focus on reconstructing two dimensional (2D) data distribution, leading to inconsistencies between adjacent slices in the reconstructed 3D volumetric images. To overcome this limitation, we propose a novel two-and-a-half order score-based model (TOSM). During the training phase, our TOSM learns data distributions in 2D space, which reduces the complexity of training compared to directly working on 3D volumes. However, in the reconstruction phase, the TOSM updates the data distribution in 3D space, utilizing complementary scores along three directions (sagittal, coronal, and transaxial) to achieve a more precise reconstruction. The development of TOSM is built on robust theoretical principles, ensuring its reliability and efficacy. Through extensive experimentation on large-scale sparse-view CT and fast MRI datasets, our method demonstrates remarkable advancements and attains state-of-the-art results in solving 3D ill-posed inverse problems. Notably, the proposed TOSM effectively addresses the inter-slice inconsistency issue, resulting in high-quality 3D volumetric reconstruction.