 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
Boosting Overlapping Organoid Instance Segmentation Using Pseudo-Label Unmixing and Synthesis-Assisted Learning
Jan 10, 2026Organoids, sophisticated in vitro models of human tissues, are crucial for medical research due to their ability to simulate organ functions and assess drug responses accurately. Accurate organoid instance segmentation is critical for quantifying their dynamic behaviors, yet remains profoundly limited by high-quality annotated datasets and pervasive overlap in microscopy imaging. While semi-supervised learning (SSL) offers a solution to alleviate reliance on scarce labeled data, conventional SSL frameworks suffer from biases induced by noisy pseudo-labels, particularly in overlapping regions. Synthesis-assisted SSL (SA-SSL) has been proposed for mitigating training biases in semi-supervised semantic segmentation. We present the first adaptation of SA-SSL to organoid instance segmentation and reveal that SA-SSL struggles to disentangle intertwined organoids, often misrepresenting overlapping instances as a single entity. To overcome this, we propose Pseudo-Label Unmixing (PLU), which identifies erroneous pseudo-labels for overlapping instances and then regenerates organoid labels through instance decomposition. For image synthesis, we apply a contour-based approach to synthesize organoid instances efficiently, particularly for overlapping cases. Instance-level augmentations (IA) on pseudo-labels before image synthesis further enhances the effect of synthetic data (SD). Rigorous experiments on two organoid datasets demonstrate our method's effectiveness, achieving performance comparable to fully supervised models using only 10% labeled data, and state-of-the-art results. Ablation studies validate the contributions of PLU, contour-based synthesis, and augmentation-aware training. By addressing overlap at both pseudo-label and synthesis levels, our work advances scalable, label-efficient organoid analysis, unlocking new potential for high-throughput applications in precision medicine.
Two-and-a-half Order Score-based Model for Solving 3D Ill-posed Inverse Problems
Aug 17, 2023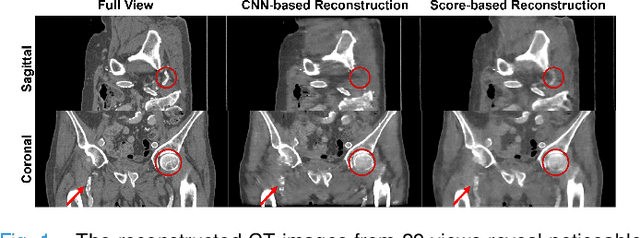

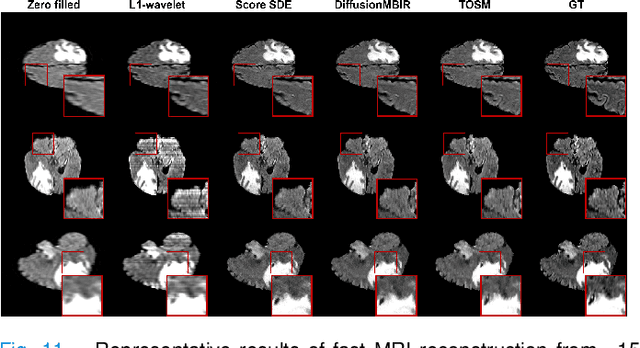

Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) are crucial technologies in the field of medical imaging. Score-based models have proven to be effective in addressing different inverse problems encountered in CT and MRI, such as sparse-view CT and fast MRI reconstruction. However, these models face challenges in achieving accurate three dimensional (3D) volumetric reconstruction. The existing score-based models primarily focus on reconstructing two dimensional (2D) data distribution, leading to inconsistencies between adjacent slices in the reconstructed 3D volumetric images. To overcome this limitation, we propose a novel two-and-a-half order score-based model (TOSM). During the training phase, our TOSM learns data distributions in 2D space, which reduces the complexity of training compared to directly working on 3D volumes. However, in the reconstruction phase, the TOSM updates the data distribution in 3D space, utilizing complementary scores along three directions (sagittal, coronal, and transaxial) to achieve a more precise reconstruction. The development of TOSM is built on robust theoretical principles, ensuring its reliability and efficacy. Through extensive experimentation on large-scale sparse-view CT and fast MRI datasets, our method demonstrates remarkable advancements and attains state-of-the-art results in solving 3D ill-posed inverse problems. Notably, the proposed TOSM effectively addresses the inter-slice inconsistency issue, resulting in high-quality 3D volumetric reconstruction.
Instance Image Retrieval by Learning Purely From Within the Dataset
Aug 12, 2022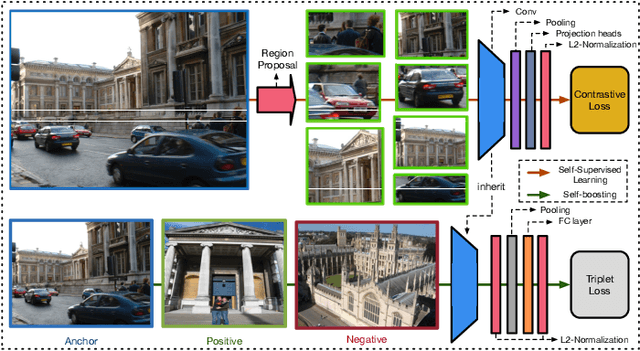
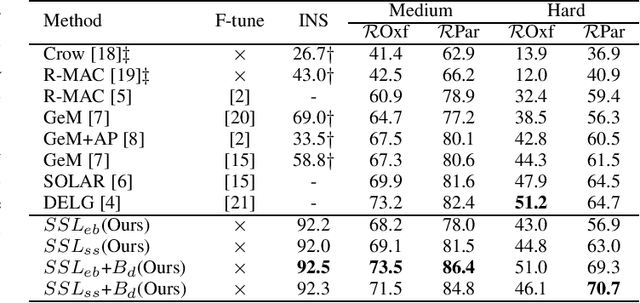

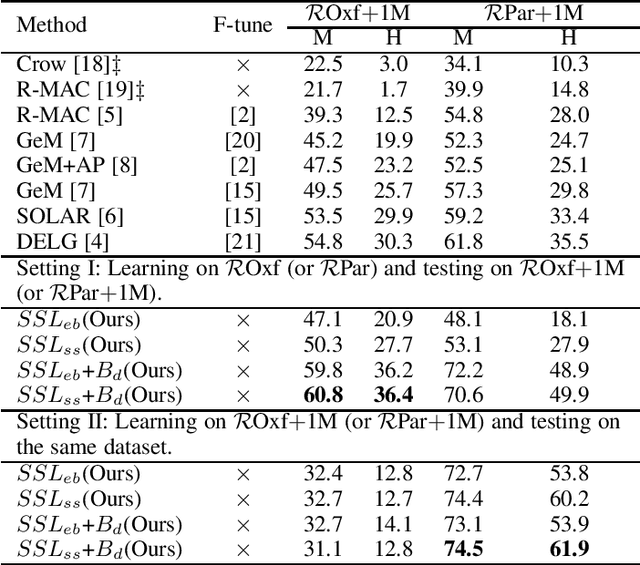
Quality feature representation is key to instance image retrieval. To attain it, existing methods usually resort to a deep model pre-trained on benchmark datasets or even fine-tune the model with a task-dependent labelled auxiliary dataset. Although achieving promising results, this approach is restricted by two issues: 1) the domain gap between benchmark datasets and the dataset of a given retrieval task; 2) the required auxiliary dataset cannot be readily obtained. In light of this situation, this work looks into a different approach which has not been well investigated for instance image retrieval previously: {can we learn feature representation \textit{specific to} a given retrieval task in order to achieve excellent retrieval?} Our finding is encouraging. By adding an object proposal generator to generate image regions for self-supervised learning, the investigated approach can successfully learn feature representation specific to a given dataset for retrieval. This representation can be made even more effective by boosting it with image similarity information mined from the dataset. As experimentally validated, such a simple ``self-supervised learning + self-boosting'' approach can well compete with the relevant state-of-the-art retrieval methods. Ablation study is conducted to show the appealing properties of this approach and its limitation on generalisation across datasets.
Triple-view Convolutional Neural Networks for COVID-19 Diagnosis with Chest X-ray
Oct 27, 2020

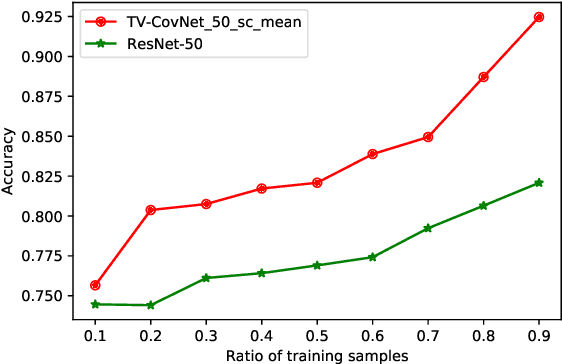
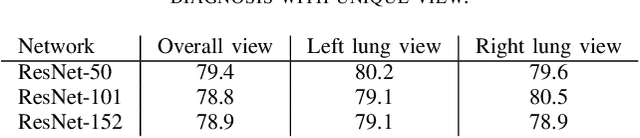
The Coronavirus Disease 2019 (COVID-19) is affecting increasingly large number of people worldwide, posing significant stress to the health care systems. Early and accurate diagnosis of COVID-19 is critical in screening of infected patients and breaking the person-to-person transmission. Chest X-ray (CXR) based computer-aided diagnosis of COVID-19 using deep learning becomes a promising solution to this end. However, the diverse and various radiographic features of COVID-19 make it challenging, especially when considering each CXR scan typically only generates one single image. Data scarcity is another issue since collecting large-scale medical CXR data set could be difficult at present. Therefore, how to extract more informative and relevant features from the limited samples available becomes essential. To address these issues, unlike traditional methods processing each CXR image from a single view, this paper proposes triple-view convolutional neural networks for COVID-19 diagnosis with CXR images. Specifically, the proposed networks extract individual features from three views of each CXR image, i.e., the left lung view, the right lung view and the overall view, in three streams and then integrate them for joint diagnosis. The proposed network structure respects the anatomical structure of human lungs and is well aligned with clinical diagnosis of COVID-19 in practice. In addition, the labeling of the views does not require experts' domain knowledge, which is needed by many existing methods. The experimental results show that the proposed method achieves state-of-the-art performance, especially in the more challenging three class classification task, and admits wide generality and high flexibility.
Exploiting Structure Sparsity for Covariance-based Visual Representation
Nov 27, 2016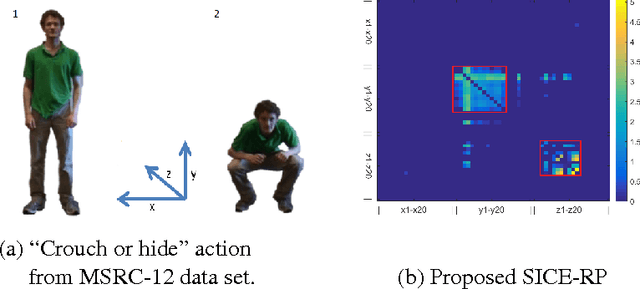
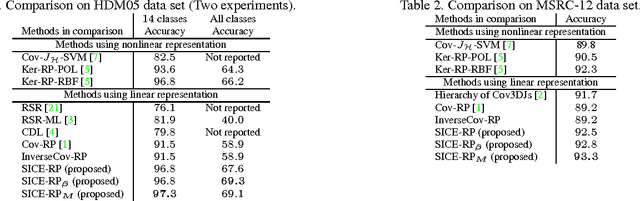


The past few years have witnessed increasing research interest on covariance-based feature representation. A variety of methods have been proposed to boost its efficacy, with some recent ones resorting to nonlinear kernel technique. Noting that the essence of this feature representation is to characterise the underlying structure of visual features, this paper argues that an equally, if not more, important approach to boosting its efficacy shall be to improve the quality of this characterisation. Following this idea, we propose to exploit the structure sparsity of visual features in skeletal human action recognition, and compute sparse inverse covariance estimate (SICE) as feature representation. We discuss the advantage of this new representation on dealing with small sample, high dimensionality, and modelling capability. Furthermore, utilising the monotonicity property of SICE, we efficiently generate a hierarchy of SICE matrices to characterise the structure of visual features at different sparsity levels, and two discriminative learning algorithms are then developed to adaptively integrate them to perform recognition. As demonstrated by extensive experiments, the proposed representation leads to significantly improved recognition performance over the state-of-the-art comparable methods. In particular, as a method fully based on linear technique, it is comparable or even better than those employing nonlinear kernel technique. This result well demonstrates the value of exploiting structure sparsity for covariance-based feature representation.
Learning Discriminative Stein Kernel for SPD Matrices and Its Applications
May 18, 2015

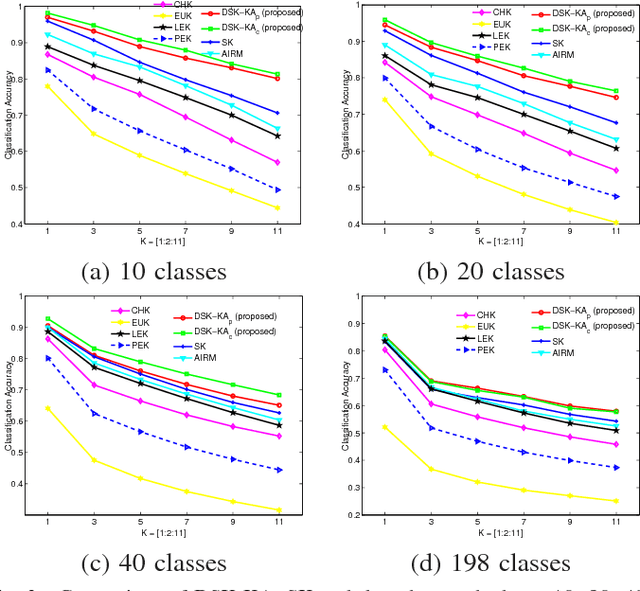
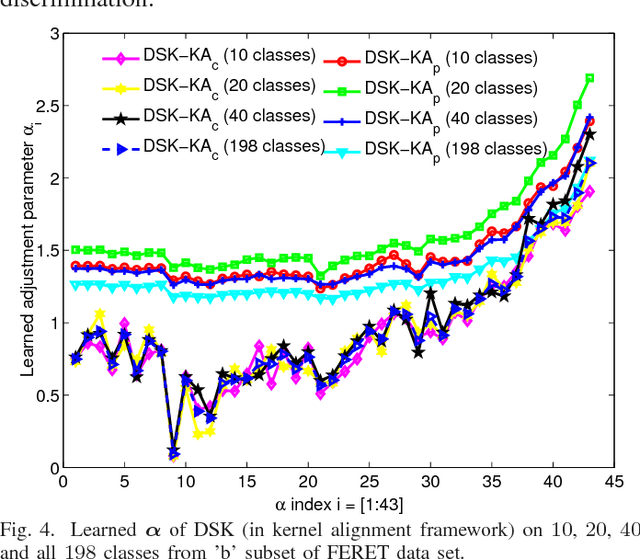
Stein kernel has recently shown promising performance on classifying images represented by symmetric positive definite (SPD) matrices. It evaluates the similarity between two SPD matrices through their eigenvalues. In this paper, we argue that directly using the original eigenvalues may be problematic because: i) Eigenvalue estimation becomes biased when the number of samples is inadequate, which may lead to unreliable kernel evaluation; ii) More importantly, eigenvalues only reflect the property of an individual SPD matrix. They are not necessarily optimal for computing Stein kernel when the goal is to discriminate different sets of SPD matrices. To address the two issues in one shot, we propose a discriminative Stein kernel, in which an extra parameter vector is defined to adjust the eigenvalues of the input SPD matrices. The optimal parameter values are sought by optimizing a proxy of classification performance. To show the generality of the proposed method, three different kernel learning criteria that are commonly used in the literature are employed respectively as a proxy. A comprehensive experimental study is conducted on a variety of image classification tasks to compare our proposed discriminative Stein kernel with the original Stein kernel and other commonly used methods for evaluating the similarity between SPD matrices. The experimental results demonstrate that, the discriminative Stein kernel can attain greater discrimination and better align with classification tasks by altering the eigenvalues. This makes it produce higher classification performance than the original Stein kernel and other commonly used methods.
HEp-2 Cell Image Classification with Deep Convolutional Neural Networks
May 18, 2015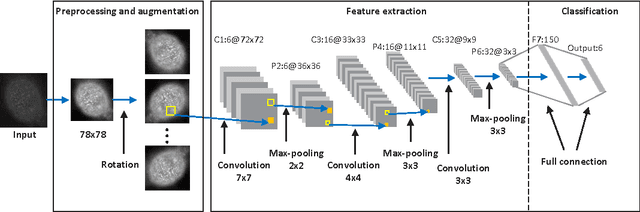



Efficient Human Epithelial-2 (HEp-2) cell image classification can facilitate the diagnosis of many autoimmune diseases. This paper presents an automatic framework for this classification task, by utilizing the deep convolutional neural networks (CNNs) which have recently attracted intensive attention in visual recognition. This paper elaborates the important components of this framework, discusses multiple key factors that impact the efficiency of training a deep CNN, and systematically compares this framework with the well-established image classification models in the literature. Experiments on benchmark datasets show that i) the proposed framework can effectively outperform existing models by properly applying data augmentation; ii) our CNN-based framework demonstrates excellent adaptability across different datasets, which is highly desirable for classification under varying laboratory settings. Our system is ranked high in the cell image classification competition hosted by ICPR 2014.