 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind CT Image Quality Assessment Using DDPM-derived Content and Transformer-based Evaluator
Oct 04, 2023Lowering radiation dose per view and utilizing sparse views per scan are two common CT scan modes, albeit often leading to distorted images characterized by noise and streak artifacts. Blind image quality assessment (BIQA) strives to evaluate perceptual quality in alignment with what radiologists perceive, which plays an important role in advancing low-dose CT reconstruction techniques. An intriguing direction involves developing BIQA methods that mimic the operational characteristic of the human visual system (HVS). The internal generative mechanism (IGM) theory reveals that the HVS actively deduces primary content to enhance comprehension. In this study, we introduce an innovative BIQA metric that emulates the active inference process of IGM. Initially, an active inference module, implemented as a denoising diffusion probabilistic model (DDPM), is constructed to anticipate the primary content. Then, the dissimilarity map is derived by assessing the interrelation between the distorted image and its primary content. Subsequently, the distorted image and dissimilarity map are combined into a multi-channel image, which is inputted into a transformer-based image quality evaluator. Remarkably, by exclusively utilizing this transformer-based quality evaluator, we won the second place in the MICCAI 2023 low-dose computed tomography perceptual image quality assessment grand challenge. Leveraging the DDPM-derived primary content, our approach further improves the performance on the challenge dataset.
AutoMO-Mixer: An automated multi-objective Mixer model for balanced, safe and robust prediction in medicine
Mar 04, 2022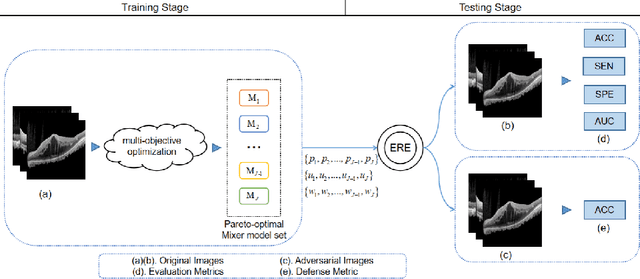
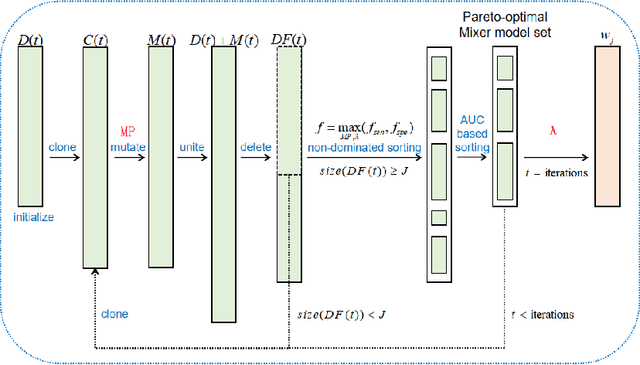
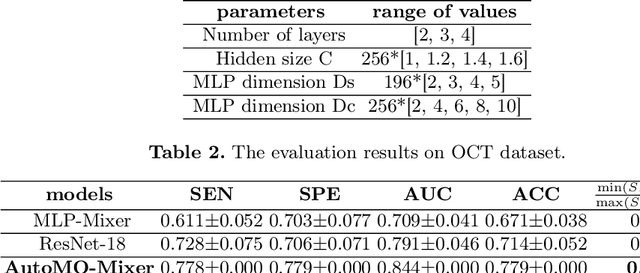
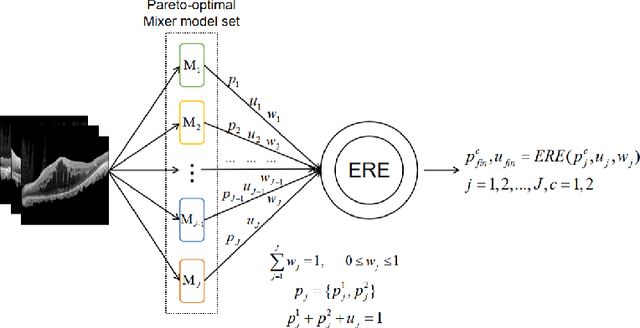
Accurately identifying patient's status through medical images plays an important role in diagnosis and treatment. Artificial intelligence (AI), especially the deep learning, has achieved great success in many fields. However, more reliable AI model is needed in image guided diagnosis and therapy. To achieve this goal, developing a balanced, safe and robust model with a unified framework is desirable. In this study, a new unified model termed as automated multi-objective Mixer (AutoMO-Mixer) model was developed, which utilized a recent developed multiple layer perceptron Mixer (MLP-Mixer) as base. To build a balanced model, sensitivity and specificity were considered as the objective functions simultaneously in training stage. Meanwhile, a new evidential reasoning based on entropy was developed to achieve a safe and robust model in testing stage. The experiment on an optical coherence tomography dataset demonstrated that AutoMO-Mixer can obtain safer, more balanced, and robust results compared with MLP-Mixer and other available models.
A Shift-insensitive Full Reference Image Quality Assessment Model Based on Quadratic Sum of Gradient Magnitude and LOG signals
Dec 21, 2020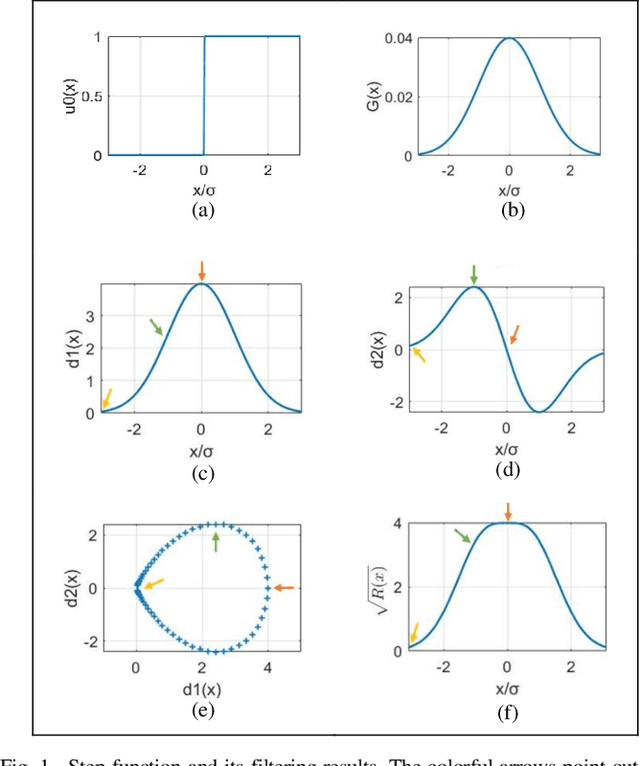
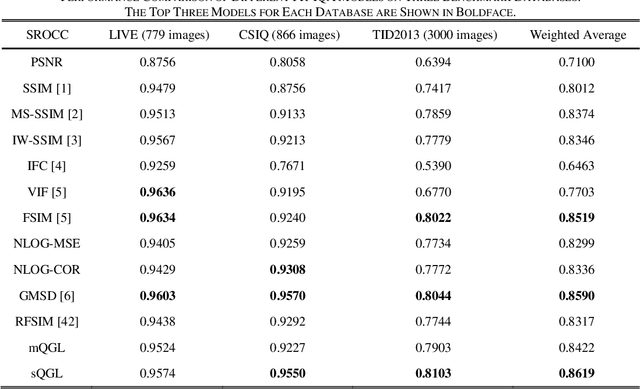

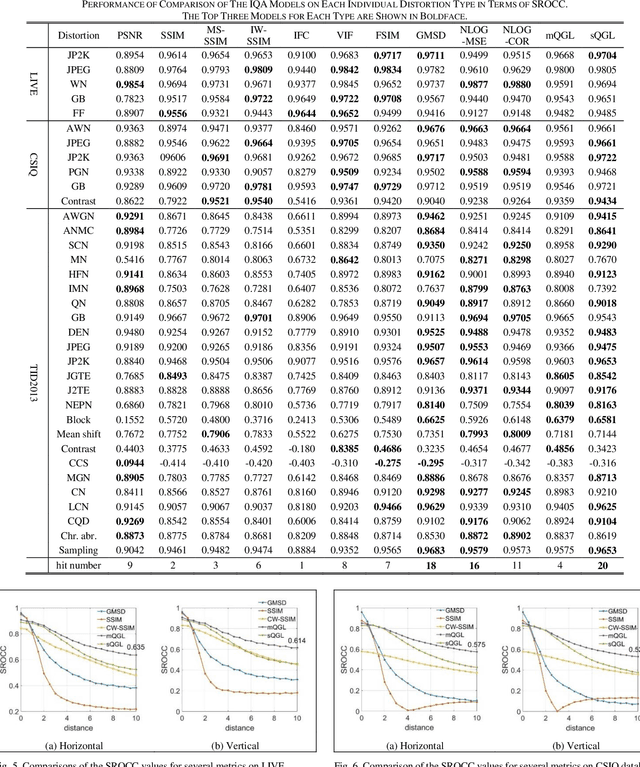
Image quality assessment that aims at estimating the subject quality of images, builds models to evaluate the perceptual quality of the image in different applications. Based on the fact that the human visual system (HVS) is highly sensitive to structural information, the edge information extraction is widely applied in different IQA metrics. According to previous studies, the image gradient magnitude (GM) and the Laplacian of Gaussian (LOG) operator are two efficient structural features in IQA tasks. However, most of the IQA metrics achieve good performance only when the distorted image is totally registered with the reference image, but fail to perform on images with small translations. In this paper, we propose an FR-IQA model with the quadratic sum of the GM and the LOG signals, which obtains good performance in image quality estimation considering shift-insensitive property for not well-registered reference and distortion image pairs. Experimental results show that the proposed model works robustly on three large scale subjective IQA databases which contain a variety of distortion types and levels, and stays in the state-of-the-art FR-IQA models no matter for single distortion type or across whole database. Furthermore, we validated that the proposed metric performs better with shift-insensitive property compared with the CW-SSIM metric that is considered to be shift-insensitive IQA so far. Meanwhile, the proposed model is much simple than the CW-SSIM, which is efficient for applications.
SSIM-Based CTU-Level Joint Optimal Bit Allocation and Rate Distortion Optimization
Apr 28, 2020



Structural similarity (SSIM)-based distortion $D_\text{SSIM}$ is more consistent with human perception than the traditional mean squared error $D_\text{MSE}$. To achieve better video quality, many studies on optimal bit allocation (OBA) and rate-distortion optimization (RDO) used $D_\text{SSIM}$ as the distortion metric. However, many of them failed to optimize OBA and RDO jointly based on SSIM, thus causing a non-optimal R-$D_\text{SSIM}$ performance. This problem is due to the lack of an accurate R-$D_\text{SSIM}$ model that can be used uniformly in both OBA and RDO. To solve this problem, we propose a $D_\text{SSIM}$-$D_\text{MSE}$ model first. Based on this model, the complex R-$D_\text{SSIM}$ cost in RDO can be calculated as simpler R-$D_\text{MSE}$ cost with a new SSIM-related Lagrange multiplier. This not only reduces the computation burden of SSIM-based RDO, but also enables the R-$D_\text{SSIM}$ model to be uniformly used in OBA and RDO. Moreover, with the new SSIM-related Lagrange multiplier in hand, the joint relationship of R-$D_\text{SSIM}$-$\lambda_\text{SSIM}$ (the negative derivative of R-$D_\text{SSIM}$) can be built, based on which the R-$D_\text{SSIM}$ model parameters can be calculated accurately. With accurate and unified R-$D_\text{SSIM}$ model, SSIM-based OBA and SSIM-based RDO are unified together in our scheme, called SOSR. Compared with the HEVC reference encoder HM16.20, SOSR saves 4%, 10%, and 14% bitrate under the same SSIM in all-intra, hierarchical and non-hierarchical low-delay-B configurations, which is superior to other state-of-the-art schemes.
Saliency detection based on structural dissimilarity induced by image quality assessment model
May 24, 2019The distinctiveness of image regions is widely used as the cue of saliency. Generally, the distinctiveness is computed according to the absolute difference of features. However, according to the image quality assessment (IQA) studies, the human visual system is highly sensitive to structural changes rather than absolute difference. Accordingly, we propose the computation of the structural dissimilarity between image patches as the distinctiveness measure for saliency detection. Similar to IQA models, the structural dissimilarity is computed based on the correlation of the structural features. The global structural dissimilarity of a patch to all the other patches represents saliency of the patch. We adopt two widely used structural features, namely the local contrast and gradient magnitude, into the structural dissimilarity computation in the proposed model. Without any postprocessing, the proposed model based on the correlation of either of the two structural features outperforms 11 state-of-the-art saliency models on three saliency databases.
* For associated source code, see https://github.com/yangli-xjtu/SDS
Low Dose CT Image Denoising Using a Generative Adversarial Network with Wasserstein Distance and Perceptual Loss
Apr 24, 2018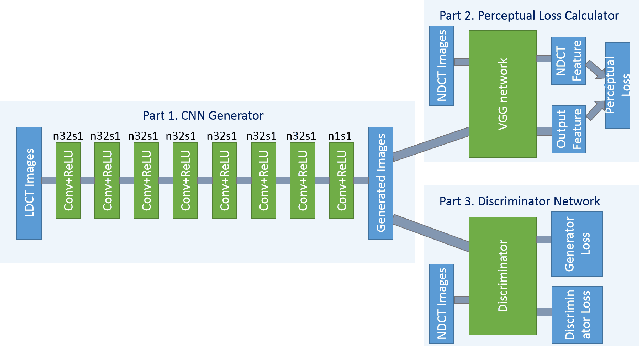
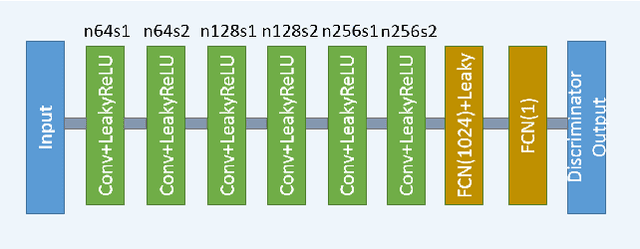
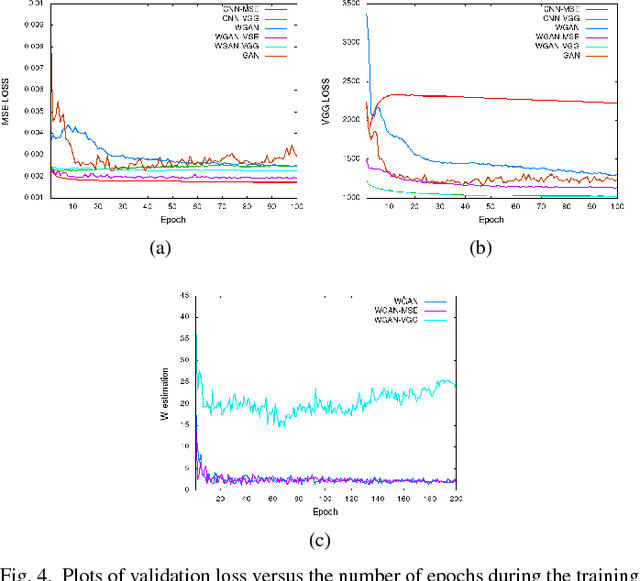
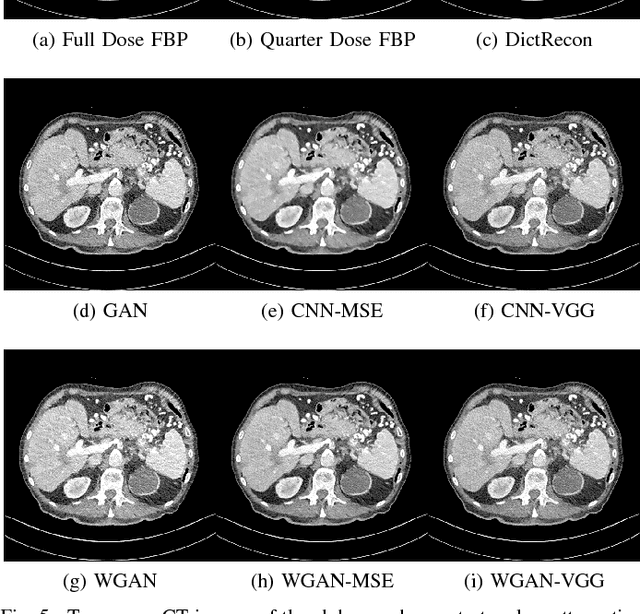
In this paper, we introduce a new CT image denoising method based on the generative adversarial network (GAN) with Wasserstein distance and perceptual similarity. The Wasserstein distance is a key concept of the optimal transform theory, and promises to improve the performance of the GAN. The perceptual loss compares the perceptual features of a denoised output against those of the ground truth in an established feature space, while the GAN helps migrate the data noise distribution from strong to weak. Therefore, our proposed method transfers our knowledge of visual perception to the image denoising task, is capable of not only reducing the image noise level but also keeping the critical information at the same time. Promising results have been obtained in our experiments with clinical CT images.
Learn to Evaluate Image Perceptual Quality Blindly from Statistics of Self-similarity
Oct 10, 2015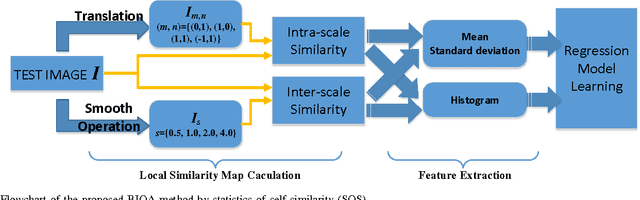

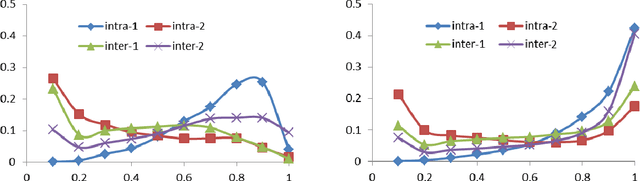
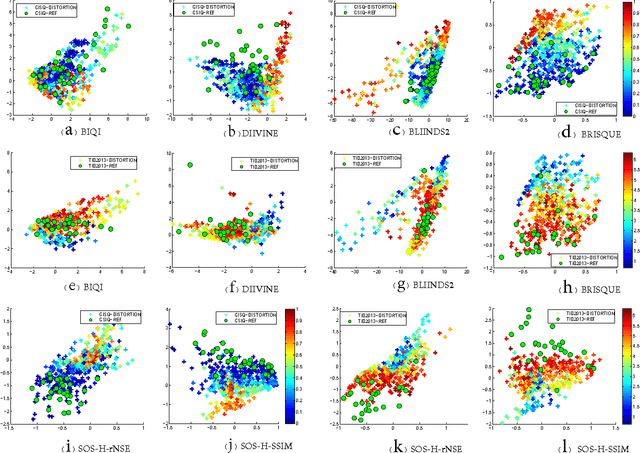
Among the various image quality assessment (IQA) tasks, blind IQA (BIQA) is particularly challenging due to the absence of knowledge about the reference image and distortion type. Features based on natural scene statistics (NSS) have been successfully used in BIQA, while the quality relevance of the feature plays an essential role to the quality prediction performance. Motivated by the fact that the early processing stage in human visual system aims to remove the signal redundancies for efficient visual coding, we propose a simple but very effective BIQA method by computing the statistics of self-similarity (SOS) in an image. Specifically, we calculate the inter-scale similarity and intra-scale similarity of the distorted image, extract the SOS features from these similarities, and learn a regression model to map the SOS features to the subjective quality score. Extensive experiments demonstrate very competitive quality prediction performance and generalization ability of the proposed SOS based BIQA method.
Gradient Magnitude Similarity Deviation: A Highly Efficient Perceptual Image Quality Index
Nov 26, 2013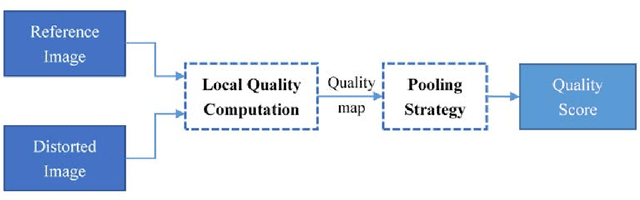


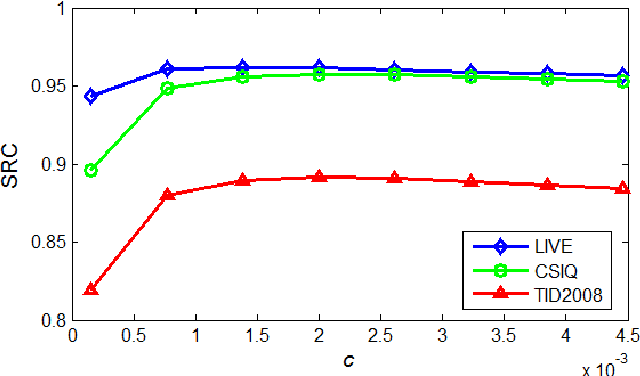
It is an important task to faithfully evaluate the perceptual quality of output images in many applications such as image compression, image restoration and multimedia streaming. A good image quality assessment (IQA) model should not only deliver high quality prediction accuracy but also be computationally efficient. The efficiency of IQA metrics is becoming particularly important due to the increasing proliferation of high-volume visual data in high-speed networks. We present a new effective and efficient IQA model, called gradient magnitude similarity deviation (GMSD). The image gradients are sensitive to image distortions, while different local structures in a distorted image suffer different degrees of degradations. This motivates us to explore the use of global variation of gradient based local quality map for overall image quality prediction. We find that the pixel-wise gradient magnitude similarity (GMS) between the reference and distorted images combined with a novel pooling strategy the standard deviation of the GMS map can predict accurately perceptual image quality. The resulting GMSD algorithm is much faster than most state-of-the-art IQA methods, and delivers highly competitive prediction accuracy.