 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoton-counting CT using a Conditional Diffusion Model for Super-resolution and Texture-preservation
Feb 25, 2024
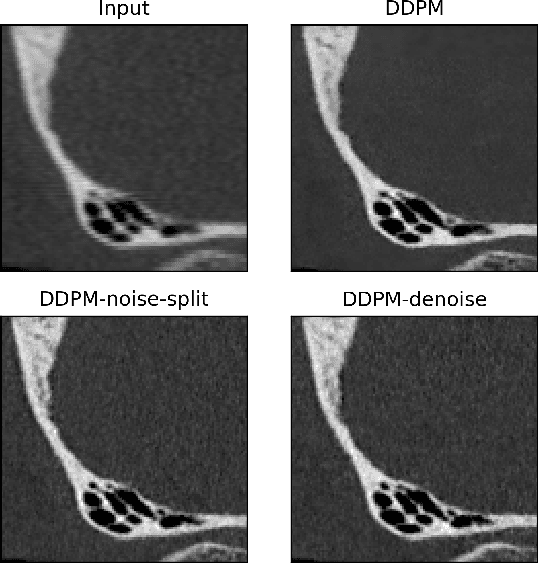
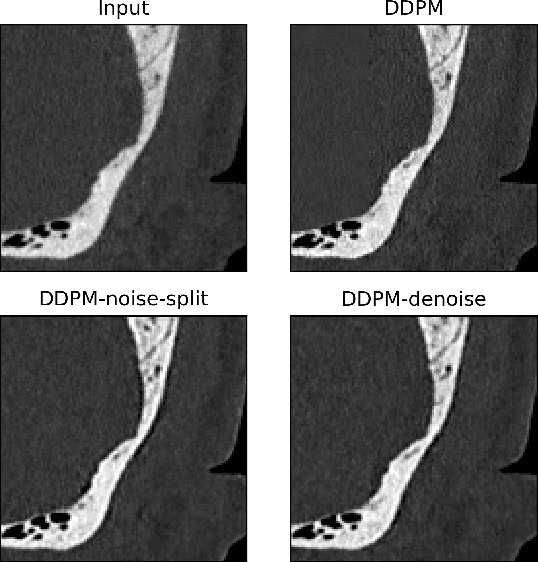
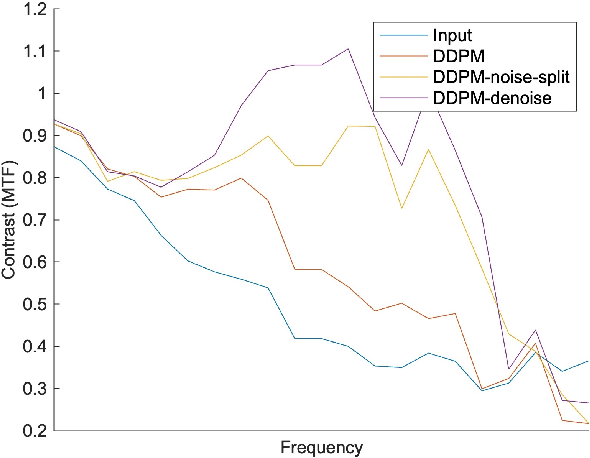
Ultra-high resolution images are desirable in photon counting CT (PCCT), but resolution is physically limited by interactions such as charge sharing. Deep learning is a possible method for super-resolution (SR), but sourcing paired training data that adequately models the target task is difficult. Additionally, SR algorithms can distort noise texture, which is an important in many clinical diagnostic scenarios. Here, we train conditional denoising diffusion probabilistic models (DDPMs) for PCCT super-resolution, with the objective to retain textural characteristics of local noise. PCCT simulation methods are used to synthesize realistic resolution degradation. To preserve noise texture, we explore decoupling the noise and signal image inputs and outputs via deep denoisers, explicitly mapping to each during the SR process. Our experimental results indicate that our DDPM trained on simulated data can improve sharpness in real PCCT images. Additionally, the disentanglement of noise from the original image allows our model more faithfully preserve noise texture.
Decorrelative Network Architecture for Robust Electrocardiogram Classification
Jul 19, 2022

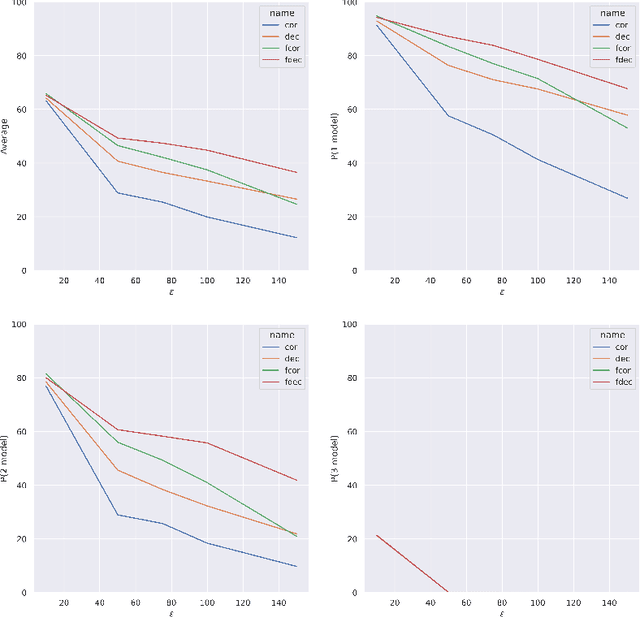
Artificial intelligence has made great progresses in medical data analysis, but the lack of robustness and interpretability has kept these methods from being widely deployed. In particular, data-driven models are vulnerable to adversarial attacks, which are small, targeted perturbations that dramatically degrade model performance. As a recent example, while deep learning has shown impressive performance in electrocardiogram (ECG) classification, Han et al. crafted realistic perturbations that fooled the network 74% of the time [2020]. Current adversarial defense paradigms are computationally intensive and impractical for many high dimensional problems. Previous research indicates that a network vulnerability is related to the features learned during training. We propose a novel approach based on ensemble decorrelation and Fourier partitioning for training parallel network arms into a decorrelated architecture to learn complementary features, significantly reducing the chance of a perturbation fooling all arms of the deep learning model. We test our approach in ECG classification, demonstrating a much-improved 77.2% chance of at least one correct network arm on the strongest adversarial attack tested, in contrast to a 21.7% chance from a comparable ensemble. Our approach does not require expensive optimization with adversarial samples, and thus can be scaled to large problems. These methods can easily be applied to other tasks for improved network robustness.
Disrupting Adversarial Transferability in Deep Neural Networks
Aug 27, 2021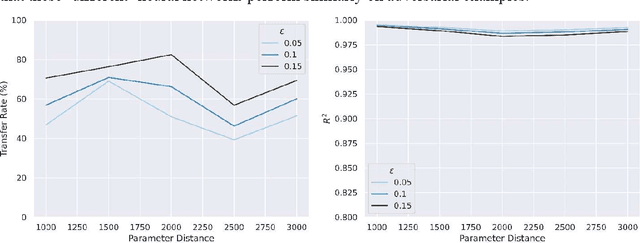
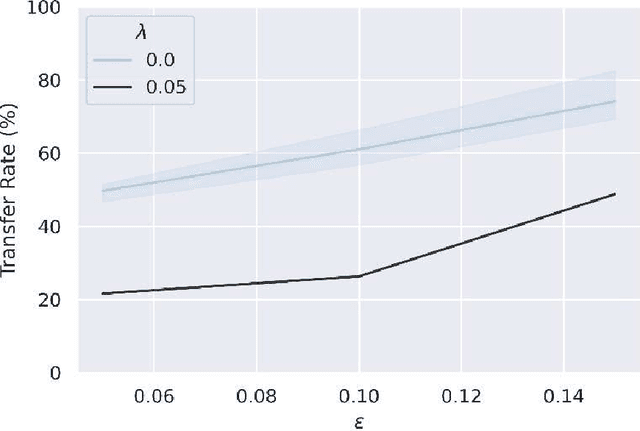
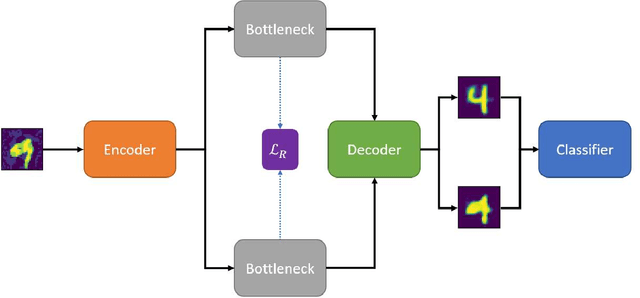
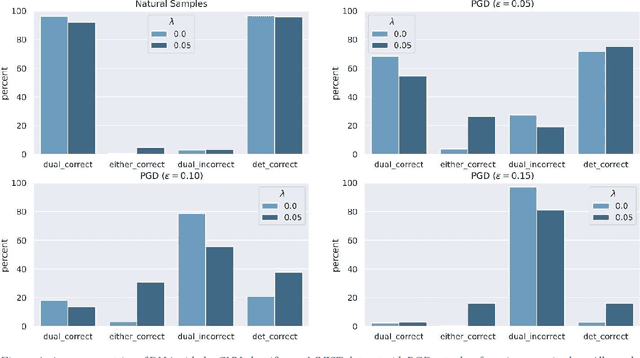
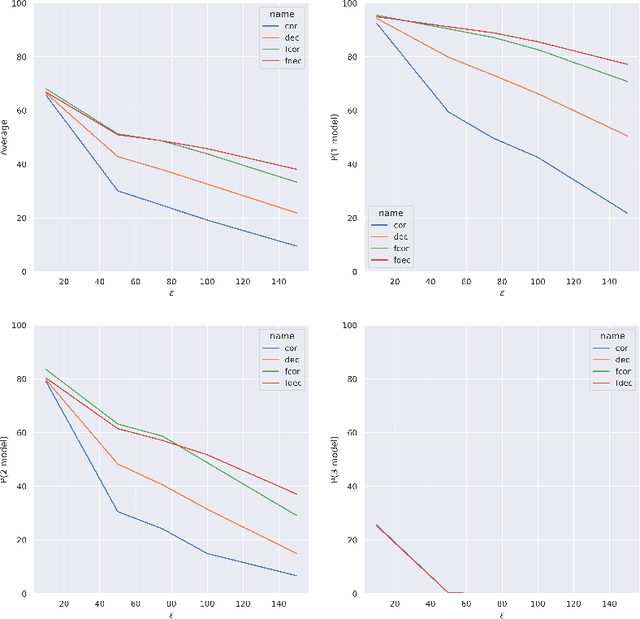
Adversarial attack transferability is a well-recognized phenomenon in deep learning. Prior work has partially explained transferability by recognizing common adversarial subspaces and correlations between decision boundaries, but we have found little explanation in the literature beyond this. In this paper, we propose that transferability between seemingly different models is due to a high linear correlation between features that different deep neural networks extract. In other words, two models trained on the same task that are seemingly distant in the parameter space likely extract features in the same fashion, just with trivial shifts and rotations between the latent spaces. Furthermore, we show how applying a feature correlation loss, which decorrelates the extracted features in a latent space, can drastically reduce the transferability of adversarial attacks between models, suggesting that the models complete tasks in semantically different ways. Finally, we propose a Dual Neck Autoencoder (DNA), which leverages this feature correlation loss to create two meaningfully different encodings of input information with reduced transferability.