 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Adversarial Transferability in Deep Neural Networks
Paper and Code
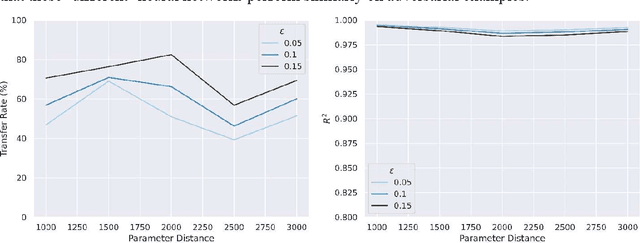
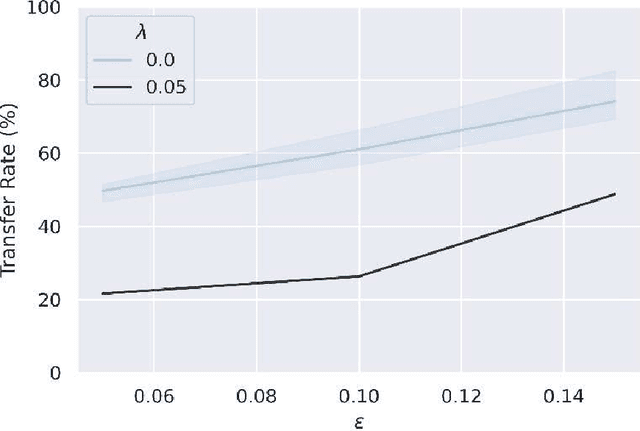
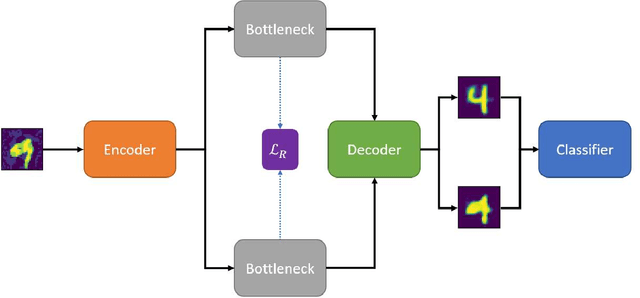
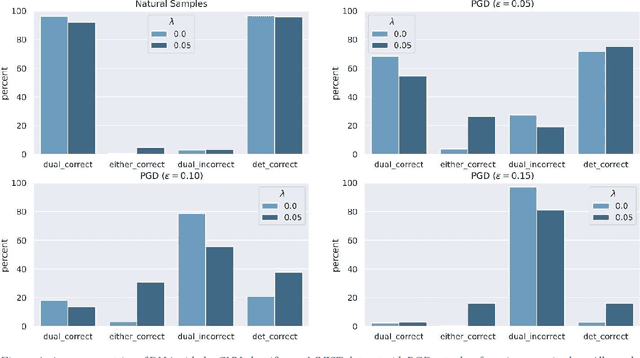
Adversarial attack transferability is a well-recognized phenomenon in deep learning. Prior work has partially explained transferability by recognizing common adversarial subspaces and correlations between decision boundaries, but we have found little explanation in the literature beyond this. In this paper, we propose that transferability between seemingly different models is due to a high linear correlation between features that different deep neural networks extract. In other words, two models trained on the same task that are seemingly distant in the parameter space likely extract features in the same fashion, just with trivial shifts and rotations between the latent spaces. Furthermore, we show how applying a feature correlation loss, which decorrelates the extracted features in a latent space, can drastically reduce the transferability of adversarial attacks between models, suggesting that the models complete tasks in semantically different ways. Finally, we propose a Dual Neck Autoencoder (DNA), which leverages this feature correlation loss to create two meaningfully different encodings of input information with reduced transferability.