 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting-based Construction of BDDs for Linear Threshold Functions and Its Application to Verification of Neural Networks
Jun 08, 2023



Understanding the characteristics of neural networks is important but difficult due to their complex structures and behaviors. Some previous work proposes to transform neural networks into equivalent Boolean expressions and apply verification techniques for characteristics of interest. This approach is promising since rich results of verification techniques for circuits and other Boolean expressions can be readily applied. The bottleneck is the time complexity of the transformation. More precisely, (i) each neuron of the network, i.e., a linear threshold function, is converted to a Binary Decision Diagram (BDD), and (ii) they are further combined into some final form, such as Boolean circuits. For a linear threshold function with $n$ variables, an existing method takes $O(n2^{\frac{n}{2}})$ time to construct an ordered BDD of size $O(2^{\frac{n}{2}})$ consistent with some variable ordering. However, it is non-trivial to choose a variable ordering producing a small BDD among $n!$ candidates. We propose a method to convert a linear threshold function to a specific form of a BDD based on the boosting approach in the machine learning literature. Our method takes $O(2^n \text{poly}(1/\rho))$ time and outputs BDD of size $O(\frac{n^2}{\rho^4}\ln{\frac{1}{\rho}})$, where $\rho$ is the margin of some consistent linear threshold function. Our method does not need to search for good variable orderings and produces a smaller expression when the margin of the linear threshold function is large. More precisely, our method is based on our new boosting algorithm, which is of independent interest. We also propose a method to combine them into the final Boolean expression representing the neural network.
Self-supervised Representation Learning for Evolutionary Neural Architecture Search
Oct 31, 2020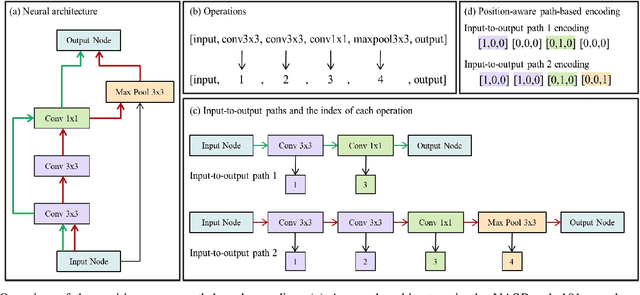
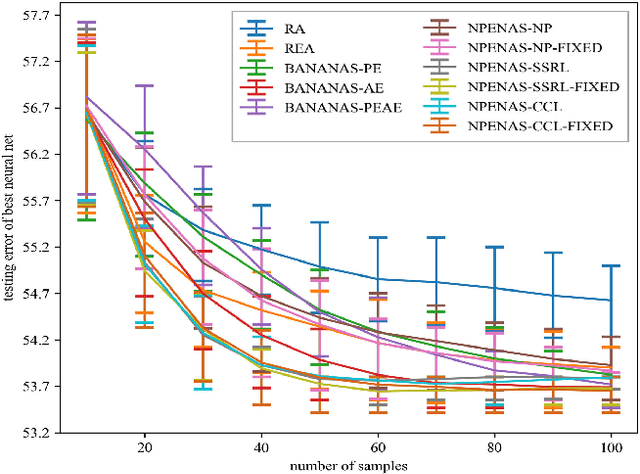
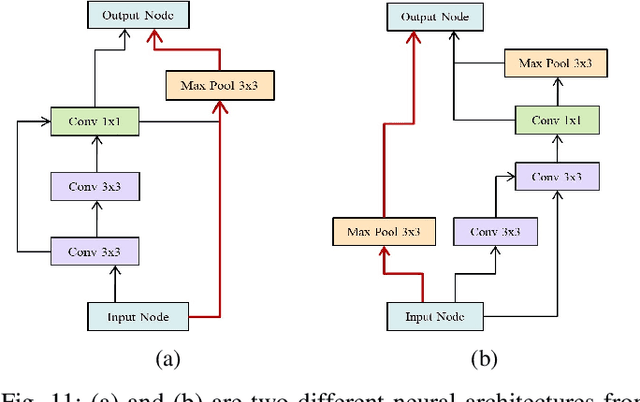
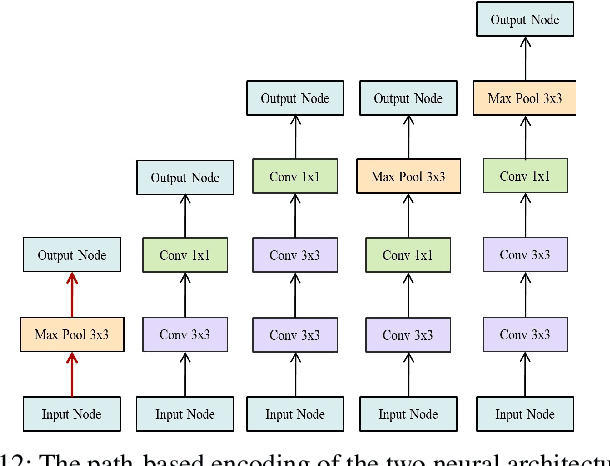
Recently proposed neural architecture search (NAS) algorithms adopt neural predictors to accelerate the architecture search. The capability of neural predictors to accurately predict the performance metrics of neural architecture is critical to NAS, and the acquisition of training datasets for neural predictors is time-consuming. How to obtain a neural predictor with high prediction accuracy using a small amount of training data is a central problem to neural predictor-based NAS. Here, we firstly design a new architecture encoding scheme that overcomes the drawbacks of existing vector-based architecture encoding schemes to calculate the graph edit distance of neural architectures. To enhance the predictive performance of neural predictors, we devise two self-supervised learning methods from different perspectives to pre-train the architecture embedding part of neural predictors to generate a meaningful representation of neural architectures. The first one is to train a carefully designed two branch graph neural network model to predict the graph edit distance of two input neural architectures. The second method is inspired by the prevalently contrastive learning, and we present a new contrastive learning algorithm that utilizes a central feature vector as a proxy to contrast positive pairs against negative pairs. Experimental results illustrate that the pre-trained neural predictors can achieve comparable or superior performance compared with their supervised counterparts with several times less training samples. We achieve state-of-the-art performance on the NASBench-101 and NASBench201 benchmarks when integrating the pre-trained neural predictors with an evolutionary NAS algorithm.
NPENAS: Neural Predictor Guided Evolution for Neural Architecture Search
Mar 28, 2020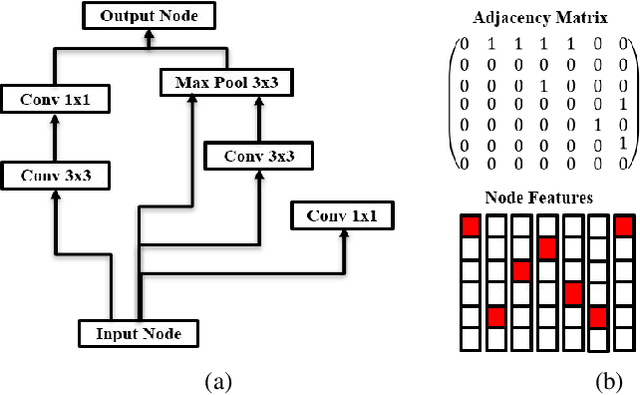
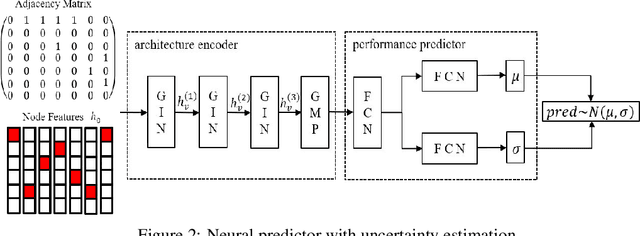
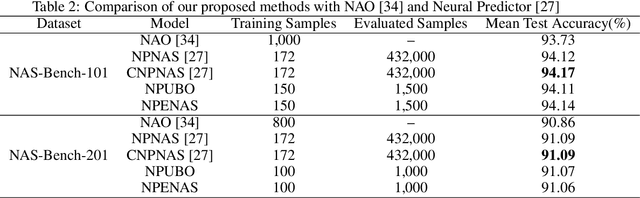
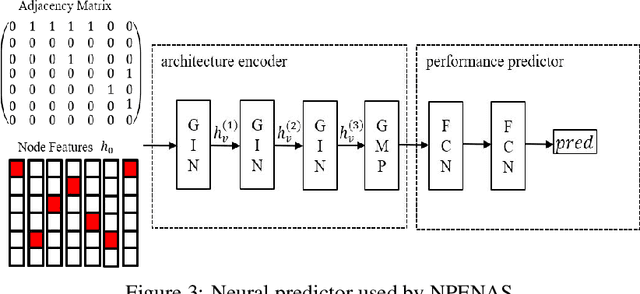
Neural architecture search (NAS) is a promising method for automatically finding excellent architectures.Commonly used search strategies such as evolutionary algorithm, Bayesian optimization, and Predictor method employs a predictor to rank sampled architectures. In this paper, we propose two predictor based algorithms NPUBO and NPENAS for neural architecture search. Firstly we propose NPUBO which takes a neural predictor with uncertainty estimation as surrogate model for Bayesian optimization. Secondly we propose a simple and effective predictor guided evolution algorithm(NPENAS), which uses neural predictor to guide evolutionary algorithm to perform selection and mutation. Finally we analyse the architecture sampling pipeline and find that mostly used random sampling pipeline tends to generate architectures in a subspace of the real underlying search space. Our proposed methods can find architecture achieves high test accuracy which is comparable with recently proposed methods on NAS-Bench-101 and NAS-Bench-201 dataset using less training and evaluated samples. Code will be publicly available after finish all the experiments.
AFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection
Oct 18, 2019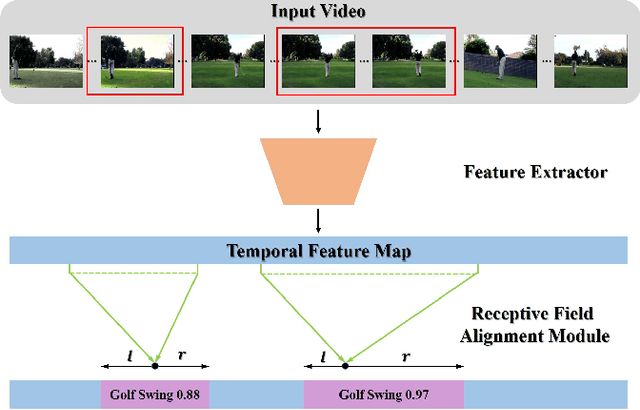
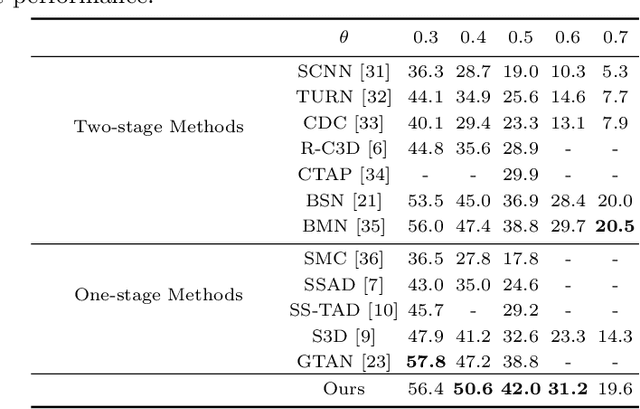
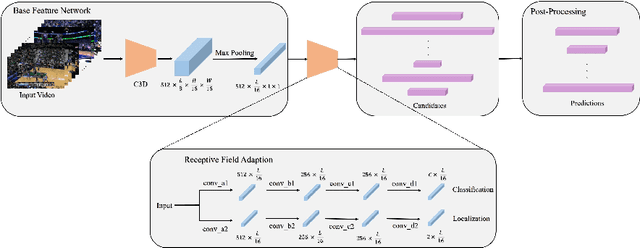
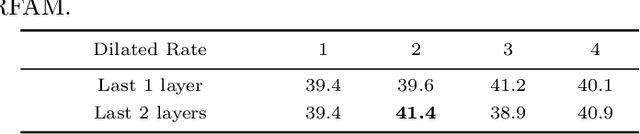
Temporal action detection is a fundamental yet challenging task in video understanding. Many of the state-of-the-art methods predict the boundaries of action instances based on predetermined anchors akin to the two-dimensional object detection detectors. However, it is hard to detect all the action instances with predetermined temporal scales because the durations of instances in untrimmed videos can vary from few seconds to several minutes. In this paper, we propose a novel action detection architecture named anchor-free one-stage temporal action detector (AFO-TAD). AFO-TAD achieves better performance for detecting action instances with arbitrary lengths and high temporal resolution, which can be attributed to two aspects. First, we design a receptive field adaption module which dynamically adjusts the receptive field for precise action detection. Second, AFO-TAD directly predicts the categories and boundaries at every temporal locations without predetermined anchors. Extensive experiments show that AFO-TAD improves the state-of-the-art performance on THUMOS'14.