 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection
Paper and Code
Oct 18, 2019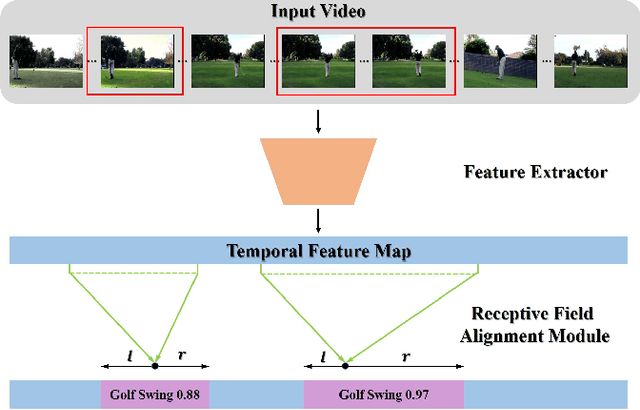
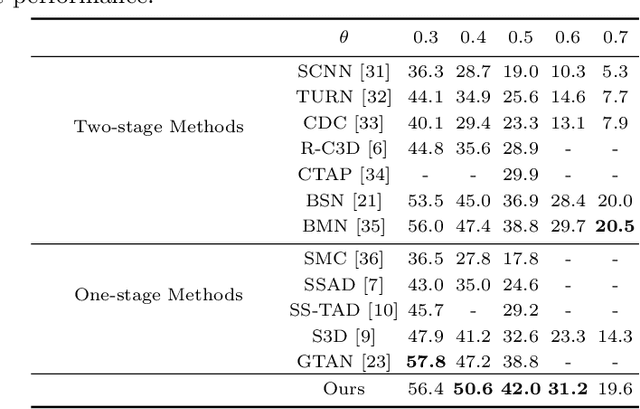
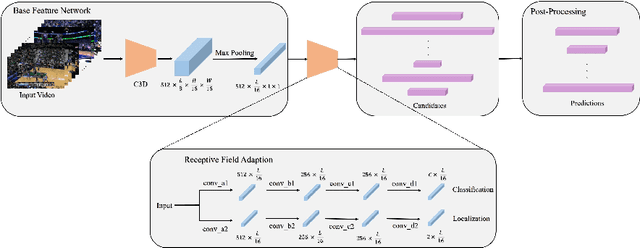
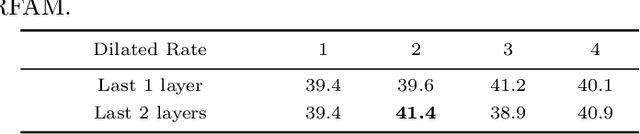
Temporal action detection is a fundamental yet challenging task in video understanding. Many of the state-of-the-art methods predict the boundaries of action instances based on predetermined anchors akin to the two-dimensional object detection detectors. However, it is hard to detect all the action instances with predetermined temporal scales because the durations of instances in untrimmed videos can vary from few seconds to several minutes. In this paper, we propose a novel action detection architecture named anchor-free one-stage temporal action detector (AFO-TAD). AFO-TAD achieves better performance for detecting action instances with arbitrary lengths and high temporal resolution, which can be attributed to two aspects. First, we design a receptive field adaption module which dynamically adjusts the receptive field for precise action detection. Second, AFO-TAD directly predicts the categories and boundaries at every temporal locations without predetermined anchors. Extensive experiments show that AFO-TAD improves the state-of-the-art performance on THUMOS'14.