 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022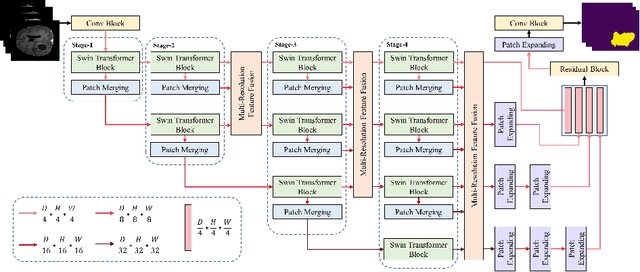

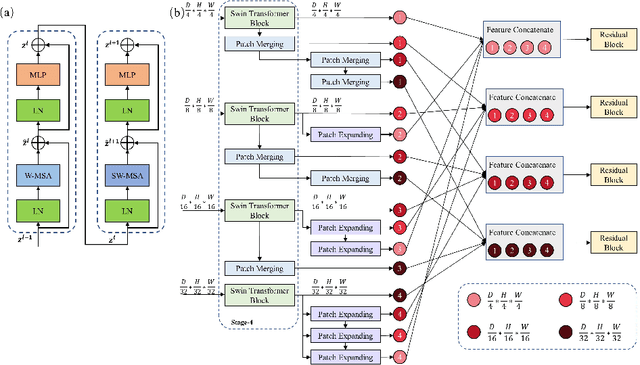

The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Phase function estimation from a diffuse optical image via deep learning
Nov 16, 2021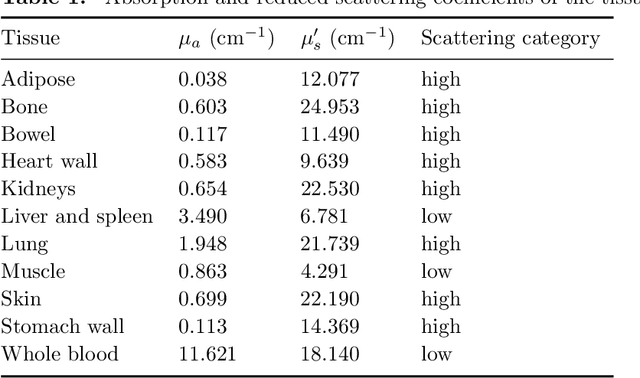
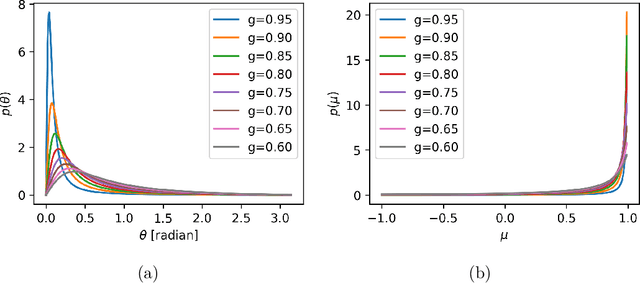


The phase function is a key element of a light propagation model for Monte Carlo (MC) simulation, which is usually fitted with an analytic function with associated parameters. In recent years, machine learning methods were reported to estimate the parameters of the phase function of a particular form such as the Henyey-Greenstein phase function but, to our knowledge, no studies have been performed to determine the form of the phase function. Here we design a convolutional neural network to estimate the phase function from a diffuse optical image without any explicit assumption on the form of the phase function. Specifically, we use a Gaussian mixture model as an example to represent the phase function generally and learn the model parameters accurately. The Gaussian mixture model is selected because it provides the analytic expression of phase function to facilitate deflection angle sampling in MC simulation, and does not significantly increase the number of free parameters. Our proposed method is validated on MC-simulated reflectance images of typical biological tissues using the Henyey-Greenstein phase function with different anisotropy factors. The effects of field of view (FOV) and spatial resolution on the errors are analyzed to optimize the estimation method. The mean squared error of the phase function is 0.01 and the relative error of the anisotropy factor is 3.28%.
AFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection
Oct 18, 2019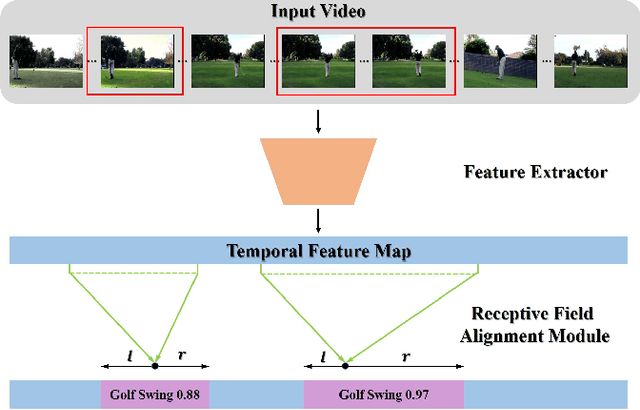
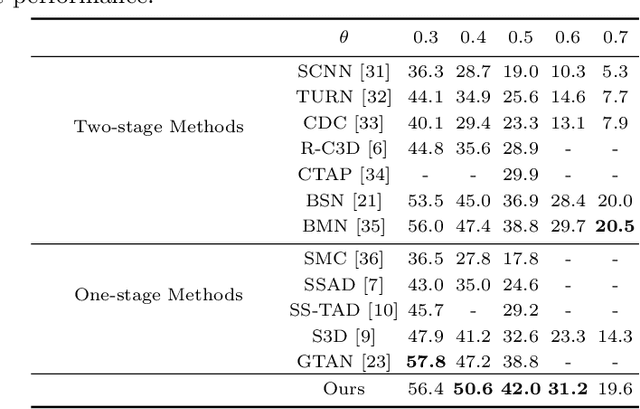
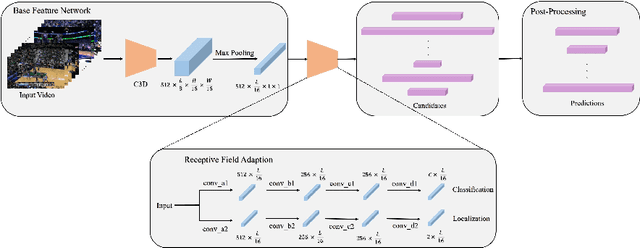
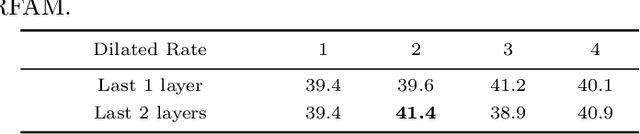
Temporal action detection is a fundamental yet challenging task in video understanding. Many of the state-of-the-art methods predict the boundaries of action instances based on predetermined anchors akin to the two-dimensional object detection detectors. However, it is hard to detect all the action instances with predetermined temporal scales because the durations of instances in untrimmed videos can vary from few seconds to several minutes. In this paper, we propose a novel action detection architecture named anchor-free one-stage temporal action detector (AFO-TAD). AFO-TAD achieves better performance for detecting action instances with arbitrary lengths and high temporal resolution, which can be attributed to two aspects. First, we design a receptive field adaption module which dynamically adjusts the receptive field for precise action detection. Second, AFO-TAD directly predicts the categories and boundaries at every temporal locations without predetermined anchors. Extensive experiments show that AFO-TAD improves the state-of-the-art performance on THUMOS'14.
DASNet: Reducing Pixel-level Annotations for Instance and Semantic Segmentation
Sep 17, 2018



Pixel-level annotation demands expensive human efforts and limits the performance of deep networks that usually benefits from more such training data. In this work we aim to achieve high quality instance and semantic segmentation results over a small set of pixel-level mask annotations and a large set of box annotations. The basic idea is exploring detection models to simplify the pixel-level supervised learning task and thus reduce the required amount of mask annotations. Our architecture, named DASNet, consists of three modules: detection, attention, and segmentation. The detection module detects all classes of objects, the attention module generates multi-scale class-specific features, and the segmentation module recovers the binary masks. Our method demonstrates substantially improved performance compared to existing semi-supervised approaches on PASCAL VOC 2012 dataset.