 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Semantics and Geometry: A Decoupled LVLM-SAM Framework for Reasoning Segmentation in Remote Sensing
Dec 22, 2025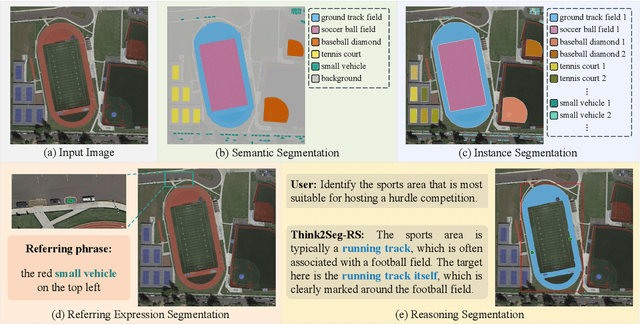
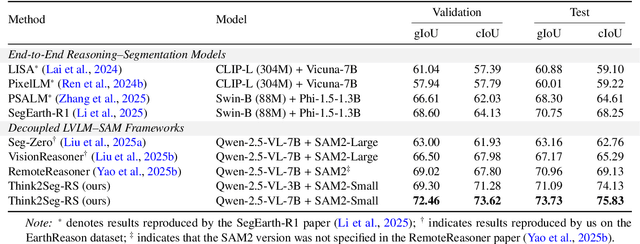
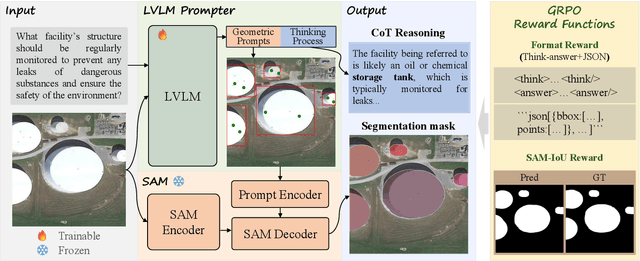
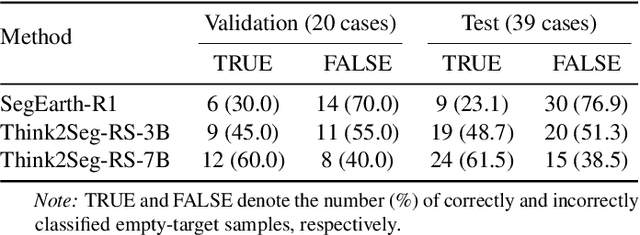
Large Vision-Language Models (LVLMs) hold great promise for advancing remote sensing (RS) analysis, yet existing reasoning segmentation frameworks couple linguistic reasoning and pixel prediction through end-to-end supervised fine-tuning, leading to weak geometric grounding and limited generalization across tasks. To address this, we developed Think2Seg-RS, a decoupled framework that trains an LVLM prompter to control a frozen Segment Anything Model (SAM) via structured geometric prompts. Through a mask-only reinforcement learning objective, the LVLM learns to translate abstract semantic reasoning into spatially grounded actions, achieving state-of-the-art performance on the EarthReason dataset. Remarkably, the learned prompting policy generalizes zero-shot to multiple referring segmentation benchmarks, exposing a distinct divide between semantic-level and instance-level grounding. We further found that compact segmenters outperform larger ones under semantic-level supervision, and that negative prompts are ineffective in heterogeneous aerial backgrounds. Together, these findings establish semantic-level reasoning segmentation as a new paradigm for geospatial understanding, opening the way toward unified, interpretable LVLM-driven Earth observation. Our code and model are available at https://github.com/Ricardo-XZ/Think2Seg-RS.
RSTeller: Scaling Up Visual Language Modeling in Remote Sensing with Rich Linguistic Semantics from Openly Available Data and Large Language Models
Aug 27, 2024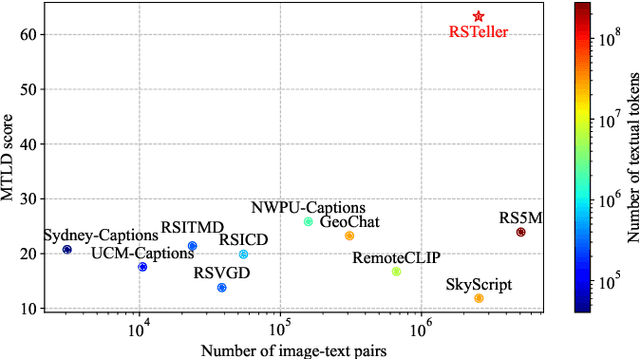

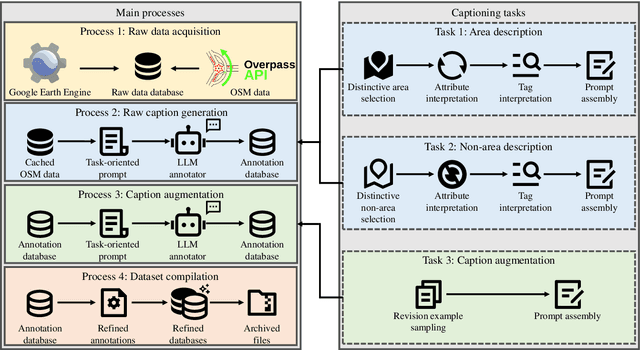

Abundant, well-annotated multimodal data in remote sensing are pivotal for aligning complex visual remote sensing (RS) scenes with human language, enabling the development of specialized vision language models across diverse RS interpretation tasks. However, annotating RS images with rich linguistic semantics at scale demands expertise in RS and substantial human labor, making it costly and often impractical. In this study, we propose a workflow that leverages large language models (LLMs) to generate multimodal datasets with semantically rich captions at scale from plain OpenStreetMap (OSM) data for images sourced from the Google Earth Engine (GEE) platform. This approach facilitates the generation of paired remote sensing data and can be readily scaled up using openly available data. Within this framework, we present RSTeller, a multimodal dataset comprising over 1 million RS images, each accompanied by multiple descriptive captions. Extensive experiments demonstrate that RSTeller enhances the performance of multiple existing vision language models for RS scene understanding through continual pre-training. Our methodology significantly reduces the manual effort and expertise needed for annotating remote sensing imagery while democratizing access to high-quality annotated data. This advancement fosters progress in visual language modeling and encourages broader participation in remote sensing research and applications. The RSTeller dataset is available at https://github.com/SlytherinGe/RSTeller.
High-Resolution Swin Transformer for Automatic Medical Image Segmentation
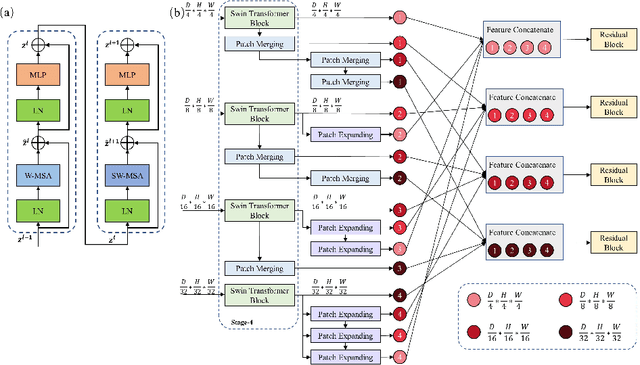
Jul 23, 2022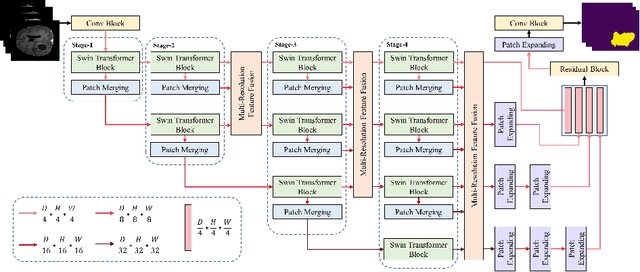


The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.