 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSTeller: Scaling Up Visual Language Modeling in Remote Sensing with Rich Linguistic Semantics from Openly Available Data and Large Language Models
Paper and Code
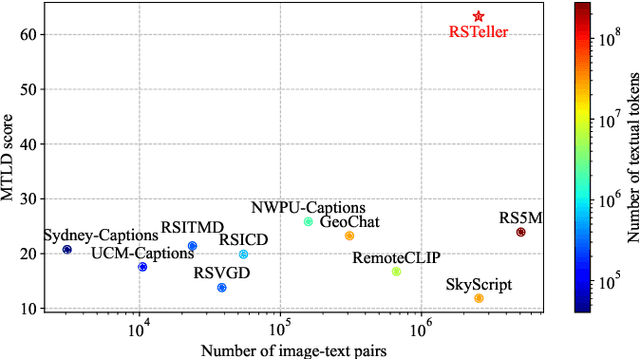

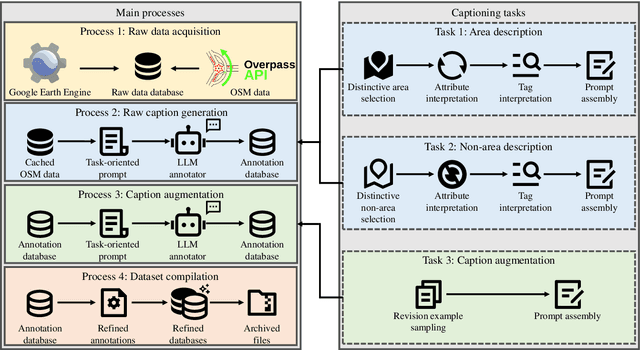

Abundant, well-annotated multimodal data in remote sensing are pivotal for aligning complex visual remote sensing (RS) scenes with human language, enabling the development of specialized vision language models across diverse RS interpretation tasks. However, annotating RS images with rich linguistic semantics at scale demands expertise in RS and substantial human labor, making it costly and often impractical. In this study, we propose a workflow that leverages large language models (LLMs) to generate multimodal datasets with semantically rich captions at scale from plain OpenStreetMap (OSM) data for images sourced from the Google Earth Engine (GEE) platform. This approach facilitates the generation of paired remote sensing data and can be readily scaled up using openly available data. Within this framework, we present RSTeller, a multimodal dataset comprising over 1 million RS images, each accompanied by multiple descriptive captions. Extensive experiments demonstrate that RSTeller enhances the performance of multiple existing vision language models for RS scene understanding through continual pre-training. Our methodology significantly reduces the manual effort and expertise needed for annotating remote sensing imagery while democratizing access to high-quality annotated data. This advancement fosters progress in visual language modeling and encourages broader participation in remote sensing research and applications. The RSTeller dataset is available at https://github.com/SlytherinGe/RSTeller.