 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinCCIR: An end-to-end deep network for Compton camera imaging reconstruction
Dec 28, 2025Compton cameras (CCs) are a kind of gamma cameras which are designed to determine the directions of incident gammas based on the Compton scatter. However, the reconstruction of CCs face problems of severe artifacts and deformation due to the fundamental reconstruction principle of back-projection of Compton cones. Besides, a part of systematic errors originated from the performance of devices are hard to remove through calibration, leading to deterioration of imaging quality. Iterative algorithms and deep-learning based methods have been widely used to improve reconstruction. But most of them are optimization based on the results of back-projection. Therefore, we proposed an end-to-end deep learning framework, SwinCCIR, for CC imaging. Through adopting swin-transformer blocks and a transposed convolution-based image generation module, we established the relationship between the list-mode events and the radioactive source distribution. SwinCCIR was trained and validated on both simulated and practical dataset. The experimental results indicate that SwinCCIR effectively overcomes problems of conventional CC imaging, which are expected to be implemented in practical applications.
Automatic extraction of coronary arteries using deep learning in invasive coronary angiograms
Jun 24, 2022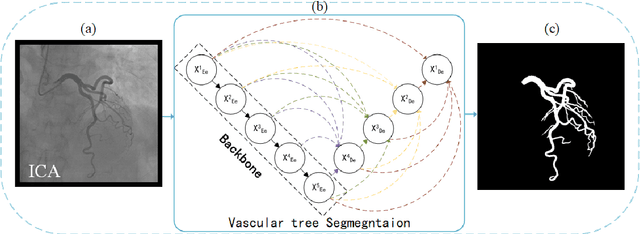
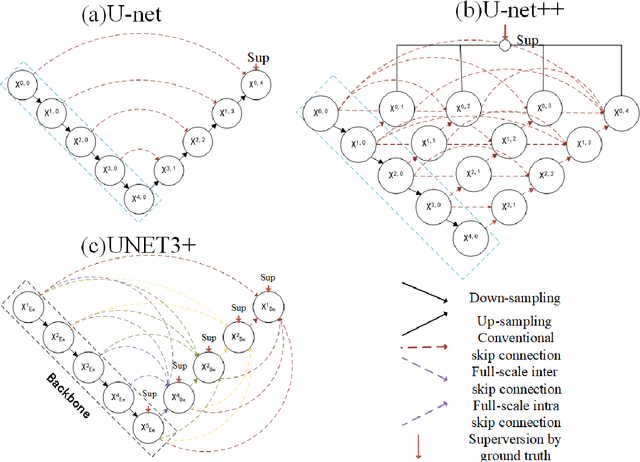

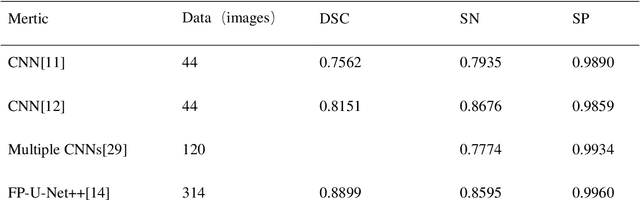
Accurate extraction of coronary arteries from invasive coronary angiography (ICA) is important in clinical decision-making for the diagnosis and risk stratification of coronary artery disease (CAD). In this study, we develop a method using deep learning to automatically extract the coronary artery lumen. Methods. A deep learning model U-Net 3+, which incorporates the full-scale skip connections and deep supervisions, was proposed for automatic extraction of coronary arteries from ICAs. Transfer learning and a hybrid loss function were employed in this novel coronary artery extraction framework. Results. A data set containing 616 ICAs obtained from 210 patients was used. In the technical evaluation, the U-Net 3+ achieved a Dice score of 0.8942 and a sensitivity of 0.8735, which is higher than U-Net ++ (Dice score: 0.8814, the sensitivity of 0.8331) and U-net (Dice score: 0.8799, the sensitivity of 0.8305). Conclusion. Our study demonstrates that the U-Net 3+ is superior to other segmentation frameworks for the automatic extraction of the coronary arteries from ICAs. This result suggests great promise for clinical use.
Automatic Identification of the End-Diastolic and End-Systolic Cardiac Frames from Invasive Coronary Angiography Videos
Oct 06, 2021
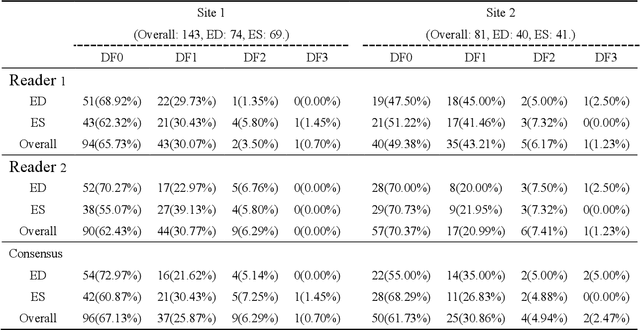
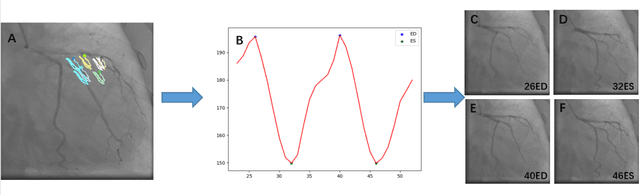
Automatic identification of proper image frames at the end-diastolic (ED) and end-systolic (ES) frames during the review of invasive coronary angiograms (ICA) is important to assess blood flow during a cardiac cycle, reconstruct the 3D arterial anatomy from bi-planar views, and generate the complementary fusion map with myocardial images. The current identification method primarily relies on visual interpretation, making it not only time-consuming but also less reproducible. In this paper, we propose a new method to automatically identify angiographic image frames associated with the ED and ES cardiac phases by using the trajectories of key vessel points (i.e. landmarks). More specifically, a detection algorithm is first used to detect the key points of coronary arteries, and then an optical flow method is employed to track the trajectories of the selected key points. The ED and ES frames are identified based on all these trajectories. Our method was tested with 62 ICA videos from two separate medical centers (22 and 9 patients in sites 1 and 2, respectively). Comparing consensus interpretations by two human expert readers, excellent agreement was achieved by the proposed algorithm: the agreement rates within a one-frame range were 92.99% and 92.73% for the automatic identification of the ED and ES image frames, respectively. In conclusion, the proposed automated method showed great potential for being an integral part of automated ICA image analysis.
AFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection
Oct 18, 2019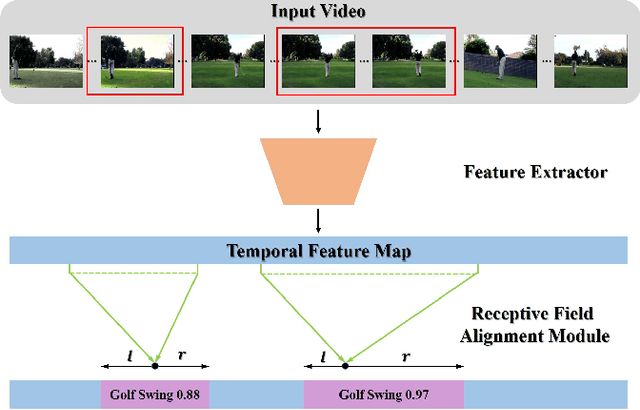
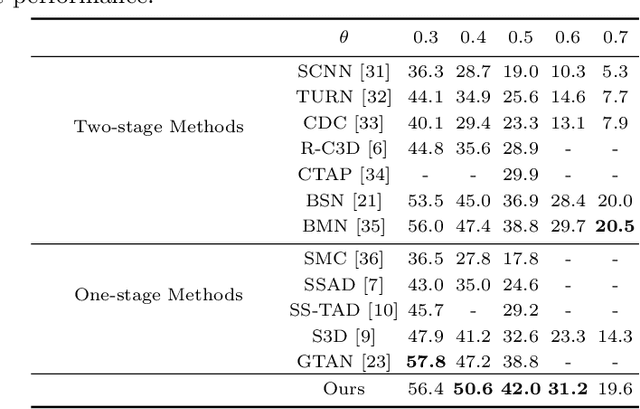
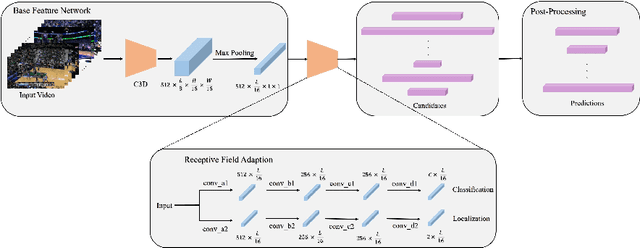
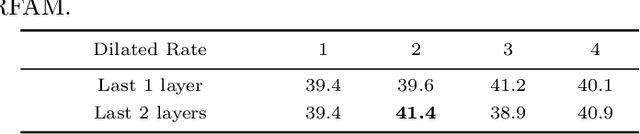
Temporal action detection is a fundamental yet challenging task in video understanding. Many of the state-of-the-art methods predict the boundaries of action instances based on predetermined anchors akin to the two-dimensional object detection detectors. However, it is hard to detect all the action instances with predetermined temporal scales because the durations of instances in untrimmed videos can vary from few seconds to several minutes. In this paper, we propose a novel action detection architecture named anchor-free one-stage temporal action detector (AFO-TAD). AFO-TAD achieves better performance for detecting action instances with arbitrary lengths and high temporal resolution, which can be attributed to two aspects. First, we design a receptive field adaption module which dynamically adjusts the receptive field for precise action detection. Second, AFO-TAD directly predicts the categories and boundaries at every temporal locations without predetermined anchors. Extensive experiments show that AFO-TAD improves the state-of-the-art performance on THUMOS'14.