 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial bandit optimization for approximately linear functions
May 27, 2025We consider a bandit optimization problem for nonconvex and non-smooth functions, where in each trial the loss function is the sum of a linear function and a small but arbitrary perturbation chosen after observing the player's choice. We give both expected and high probability regret bounds for the problem. Our result also implies an improved high-probability regret bound for the bandit linear optimization, a special case with no perturbation. We also give a lower bound on the expected regret.
Multi-objective Good Arm Identification with Bandit Feedback
Mar 13, 2025We consider a good arm identification problem in a stochastic bandit setting with multi-objectives, where each arm $i\in[K]$ is associated with $M$ distributions $\mathcal{D}_i^{(1)}, \ldots, \mathcal{D}_i^{(M)}$. For each round $t$, the player/algorithm pulls one arm $i_t$ and receives a vector feedback, where each component $m$ is sampled according to $\mathcal{D}_i^{(m)}$. The target is twofold, one is finding one arm whose means are larger than the predefined thresholds $\xi_1,\ldots,\xi_M$ with a confidence bound $\delta$ and an accuracy rate $\epsilon$ with a bounded sample complexity, the other is output $\bot$ to indicate no such arm exists. We propose an algorithm with a sample complexity bound. When $M=1$ and $\epsilon = 0$, our bound is the same as the one given in the previous work when and novel bounds for $M > 1$. The proposed algorithm attains better numerical performance than other baselines in the experiments on synthetic and real datasets.
An Improved Metarounding Algorithm via Frank-Wolfe
Oct 19, 2023Metarounding is an approach to convert an approximation algorithm for linear optimization over some combinatorial classes to an online linear optimization algorithm for the same class. We propose a new metarounding algorithm under a natural assumption that a relax-based approximation algorithm exists for the combinatorial class. Our algorithm is much more efficient in both theoretical and practical aspects.
Pure exploration in multi-armed bandits with low rank structure using oblivious sampler
Jun 28, 2023
In this paper, we consider the low rank structure of the reward sequence of the pure exploration problems. Firstly, we propose the separated setting in pure exploration problem, where the exploration strategy cannot receive the feedback of its explorations. Due to this separation, it requires that the exploration strategy to sample the arms obliviously. By involving the kernel information of the reward vectors, we provide efficient algorithms for both time-varying and fixed cases with regret bound $O(d\sqrt{(\ln N)/n})$. Then, we show the lower bound to the pure exploration in multi-armed bandits with low rank sequence. There is an $O(\sqrt{\ln N})$ gap between our upper bound and the lower bound.
Boosting-based Construction of BDDs for Linear Threshold Functions and Its Application to Verification of Neural Networks
Jun 08, 2023Understanding the characteristics of neural networks is important but difficult due to their complex structures and behaviors. Some previous work proposes to transform neural networks into equivalent Boolean expressions and apply verification techniques for characteristics of interest. This approach is promising since rich results of verification techniques for circuits and other Boolean expressions can be readily applied. The bottleneck is the time complexity of the transformation. More precisely, (i) each neuron of the network, i.e., a linear threshold function, is converted to a Binary Decision Diagram (BDD), and (ii) they are further combined into some final form, such as Boolean circuits. For a linear threshold function with $n$ variables, an existing method takes $O(n2^{\frac{n}{2}})$ time to construct an ordered BDD of size $O(2^{\frac{n}{2}})$ consistent with some variable ordering. However, it is non-trivial to choose a variable ordering producing a small BDD among $n!$ candidates. We propose a method to convert a linear threshold function to a specific form of a BDD based on the boosting approach in the machine learning literature. Our method takes $O(2^n \text{poly}(1/\rho))$ time and outputs BDD of size $O(\frac{n^2}{\rho^4}\ln{\frac{1}{\rho}})$, where $\rho$ is the margin of some consistent linear threshold function. Our method does not need to search for good variable orderings and produces a smaller expression when the margin of the linear threshold function is large. More precisely, our method is based on our new boosting algorithm, which is of independent interest. We also propose a method to combine them into the final Boolean expression representing the neural network.
Boosting as Frank-Wolfe
Sep 30, 2022
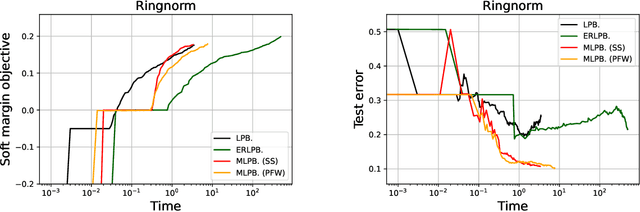
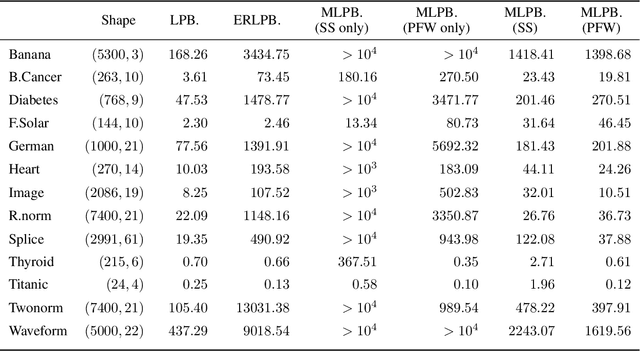
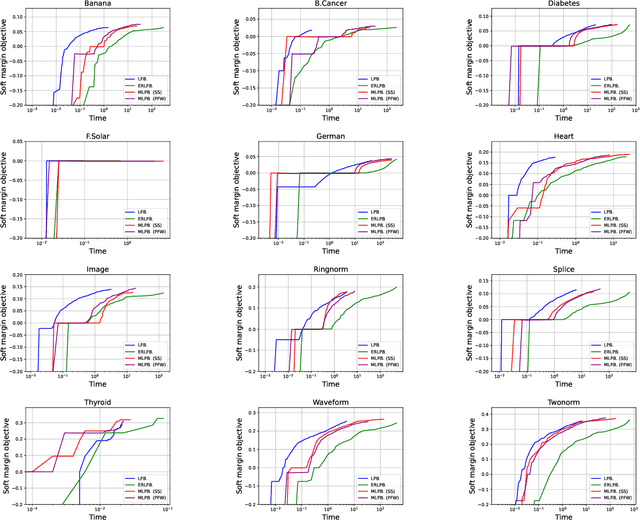
Some boosting algorithms, such as LPBoost, ERLPBoost, and C-ERLPBoost, aim to solve the soft margin optimization problem with the $\ell_1$-norm regularization. LPBoost rapidly converges to an $\epsilon$-approximate solution in practice, but it is known to take $\Omega(m)$ iterations in the worst case, where $m$ is the sample size. On the other hand, ERLPBoost and C-ERLPBoost are guaranteed to converge to an $\epsilon$-approximate solution in $O(\frac{1}{\epsilon^2} \ln \frac{m}{\nu})$ iterations. However, the computation per iteration is very high compared to LPBoost. To address this issue, we propose a generic boosting scheme that combines the Frank-Wolfe algorithm and any secondary algorithm and switches one to the other iteratively. We show that the scheme retains the same convergence guarantee as ERLPBoost and C-ERLPBoost. One can incorporate any secondary algorithm to improve in practice. This scheme comes from a unified view of boosting algorithms for soft margin optimization. More specifically, we show that LPBoost, ERLPBoost, and C-ERLPBoost are instances of the Frank-Wolfe algorithm. In experiments on real datasets, one of the instances of our scheme exploits the better updates of the secondary algorithm and performs comparably with LPBoost.
A generalised log-determinant regularizer for online semi-definite programming and its applications
Dec 11, 2020We consider a variant of online semi-definite programming problem (OSDP): The decision space consists of semi-definite matrices with bounded $\Gamma$-trace norm, which is a generalization of trace norm defined by a positive definite matrix $\Gamma.$ To solve this problem, we utilise the follow-the-regularized-leader algorithm with a $\Gamma$-dependent log-determinant regularizer. Then we apply our generalised setting and our proposed algorithm to online matrix completion(OMC) and online similarity prediction with side information. In particular, we reduce the online matrix completion problem to the generalised OSDP problem, and the side information is represented as the $\Gamma$ matrix. Hence, due to our regret bound for the generalised OSDP, we obtain an optimal mistake bound for the OMC by removing the logarithmic factor.
Improved algorithms for online load balancing
Jul 21, 2020We consider an online load balancing problem and its extensions in the framework of repeated games. On each round, the player chooses a distribution (task allocation) over $K$ servers, and then the environment reveals the load of each server, which determines the computation time of each server for processing the task assigned. After all rounds, the cost of the player is measured by some norm of the cumulative computation-time vector. The cost is the makespan if the norm is $L_\infty$-norm. The goal is to minimize the regret, i.e., minimizing the player's cost relative to the cost of the best fixed distribution in hindsight. We propose algorithms for general norms and prove their regret bounds. In particular, for $L_\infty$-norm, our regret bound matches the best known bound and the proposed algorithm runs in polynomial time per trial involving linear programming and second order programming, whereas no polynomial time algorithm was previously known to achieve the bound.
Theory and Algorithms for Shapelet-based Multiple-Instance Learning
Jun 12, 2020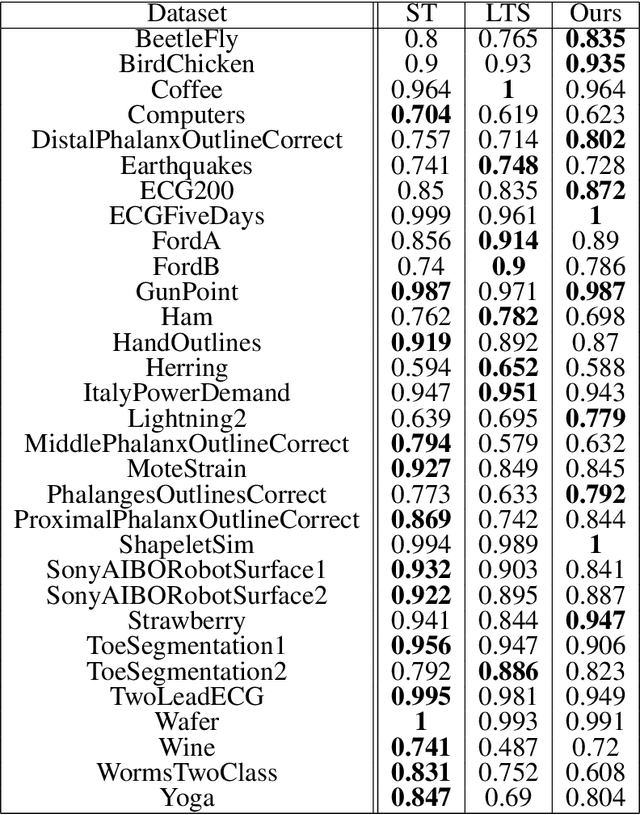
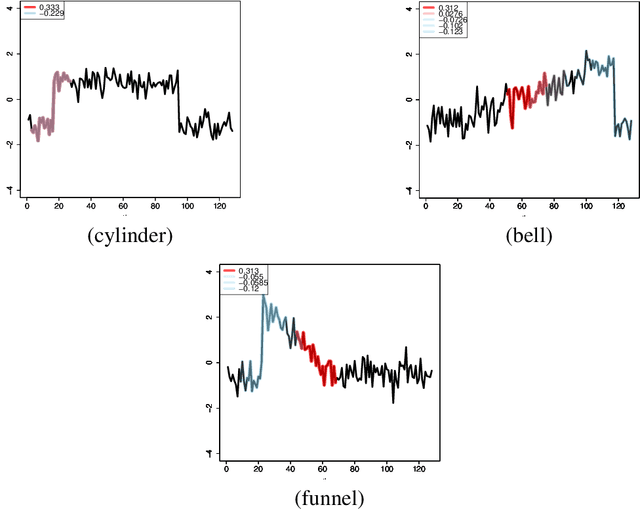
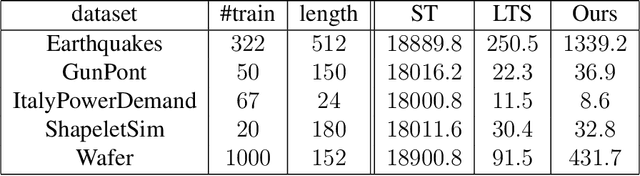
We propose a new formulation of Multiple-Instance Learning (MIL), in which a unit of data consists of a set of instances called a bag. The goal is to find a good classifier of bags based on the similarity with a "shapelet" (or pattern), where the similarity of a bag with a shapelet is the maximum similarity of instances in the bag. In previous work, some of the training instances are chosen as shapelets with no theoretical justification. In our formulation, we use all possible, and thus infinitely many shapelets, resulting in a richer class of classifiers. We show that the formulation is tractable, that is, it can be reduced through Linear Programming Boosting (LPBoost) to Difference of Convex (DC) programs of finite (actually polynomial) size. Our theoretical result also gives justification to the heuristics of some of the previous work. The time complexity of the proposed algorithm highly depends on the size of the set of all instances in the training sample. To apply to the data containing a large number of instances, we also propose a heuristic option of the algorithm without the loss of the theoretical guarantee. Our empirical study demonstrates that our algorithm uniformly works for Shapelet Learning tasks on time-series classification and various MIL tasks with comparable accuracy to the existing methods. Moreover, we show that the proposed heuristics allow us to achieve the result with reasonable computational time.
Multiple-Instance Learning by Boosting Infinitely Many Shapelet-based Classifiers
Dec 10, 2018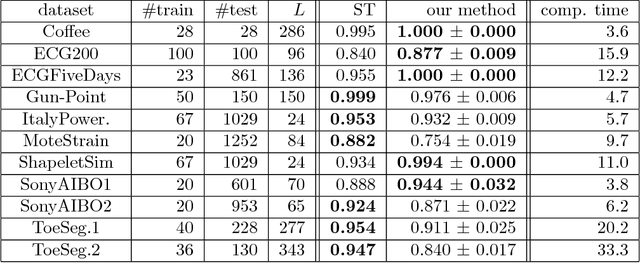

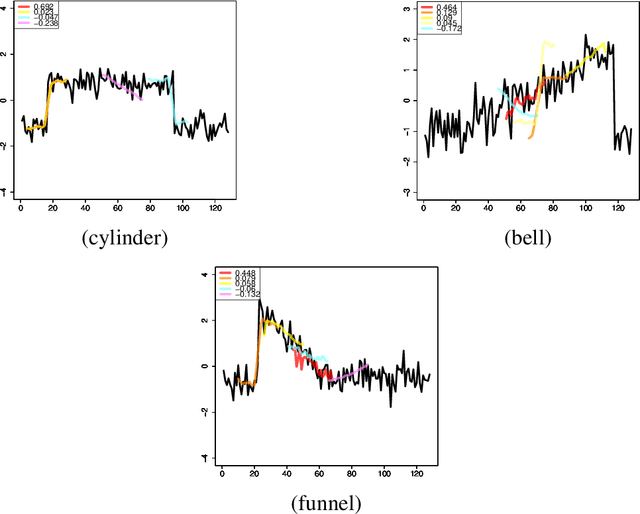
We propose a new formulation of Multiple-Instance Learning (MIL). In typical MIL settings, a unit of data is given as a set of instances called a bag and the goal is to find a good classifier of bags based on similarity from a single or finitely many "shapelets" (or patterns), where the similarity of the bag from a shapelet is the maximum similarity of instances in the bag. Classifiers based on a single shapelet are not sufficiently strong for certain applications. Additionally, previous work with multiple shapelets has heuristically chosen some of the instances as shapelets with no theoretical guarantee of its generalization ability. Our formulation provides a richer class of the final classifiers based on infinitely many shapelets. We provide an efficient algorithm for the new formulation, in addition to generalization bound. Our empirical study demonstrates that our approach is effective not only for MIL tasks but also for Shapelet Learning for time-series classification.