Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Interpretability of Artificial Neural Networks
Paper and Code
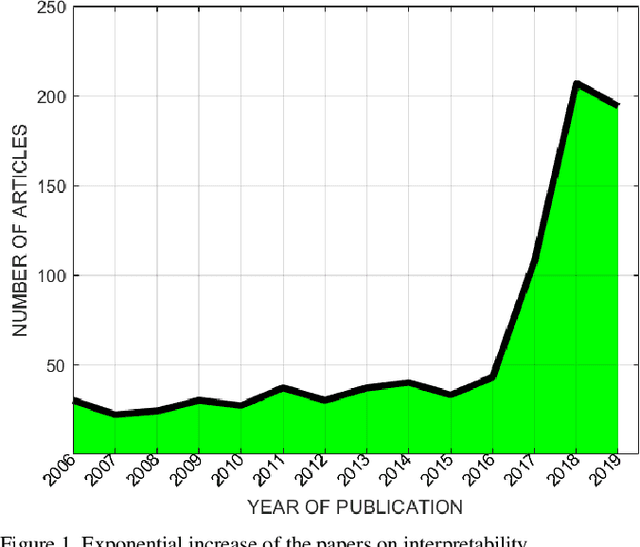
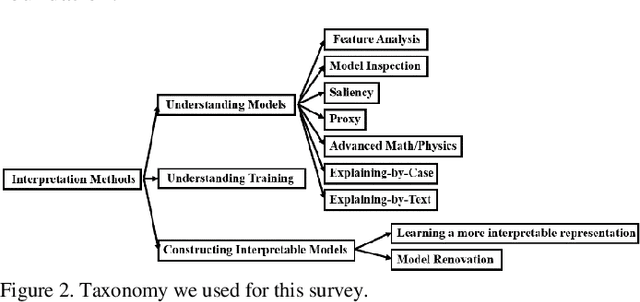

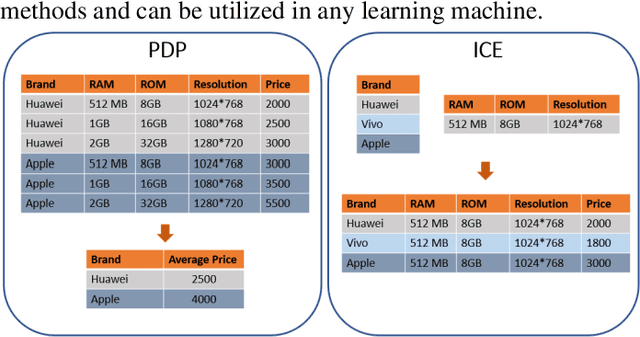
Deep learning has achieved great successes in many important areas to dealing with text, images, video, graphs, and so on. However, the black-box nature of deep artificial neural networks has become the primary obstacle to their public acceptance and wide popularity in critical applications such as diagnosis and therapy. Due to the huge potential of deep learning, interpreting neural networks has become one of the most critical research directions. In this paper, we systematically review recent studies in understanding the mechanism of neural networks and shed light on some future directions of interpretability research (This work is still in progress).
View paper on