 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDNeRF: Few-shot Dynamic Neural Radiance Fields for Face Reconstruction and Expression Editing
Paper and Code

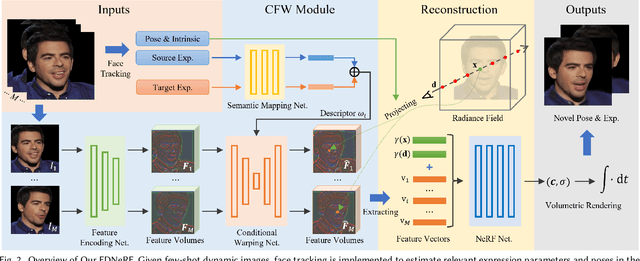

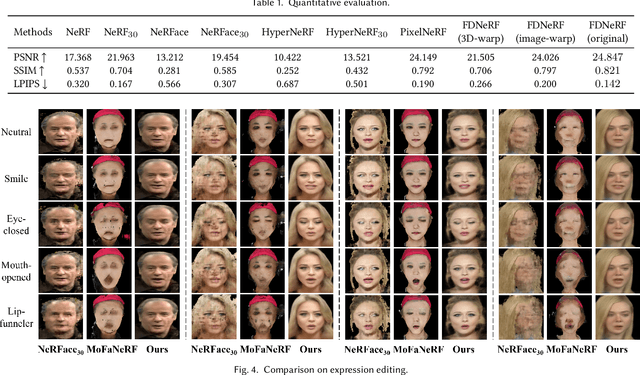
We propose a Few-shot Dynamic Neural Radiance Field (FDNeRF), the first NeRF-based method capable of reconstruction and expression editing of 3D faces based on a small number of dynamic images. Unlike existing dynamic NeRFs that require dense images as input and can only be modeled for a single identity, our method enables face reconstruction across different persons with few-shot inputs. Compared to state-of-the-art few-shot NeRFs designed for modeling static scenes, the proposed FDNeRF accepts view-inconsistent dynamic inputs and supports arbitrary facial expression editing, i.e., producing faces with novel expressions beyond the input ones. To handle the inconsistencies between dynamic inputs, we introduce a well-designed conditional feature warping (CFW) module to perform expression conditioned warping in 2D feature space, which is also identity adaptive and 3D constrained. As a result, features of different expressions are transformed into the target ones. We then construct a radiance field based on these view-consistent features and use volumetric rendering to synthesize novel views of the modeled faces. Extensive experiments with quantitative and qualitative evaluation demonstrate that our method outperforms existing dynamic and few-shot NeRFs on both 3D face reconstruction and expression editing tasks. Our code and model will be available upon acceptance.