 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe THUEE System Description for the IARPA OpenASR21 Challenge
Jun 29, 2022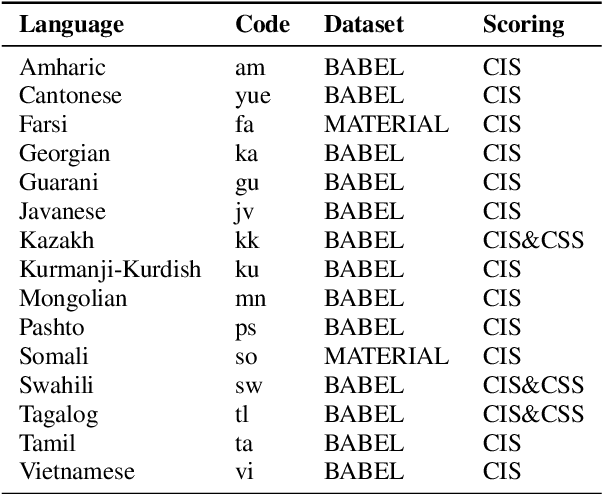
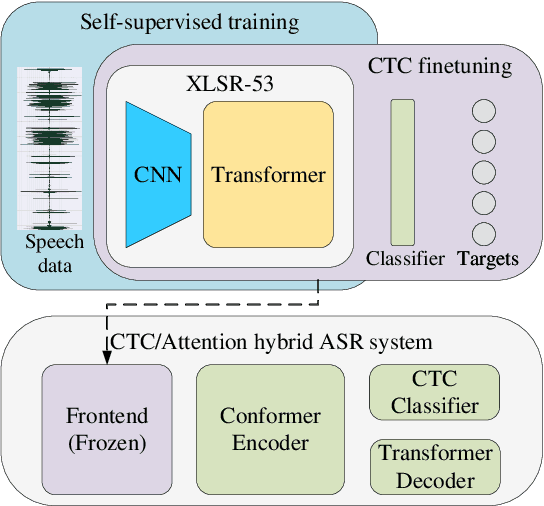
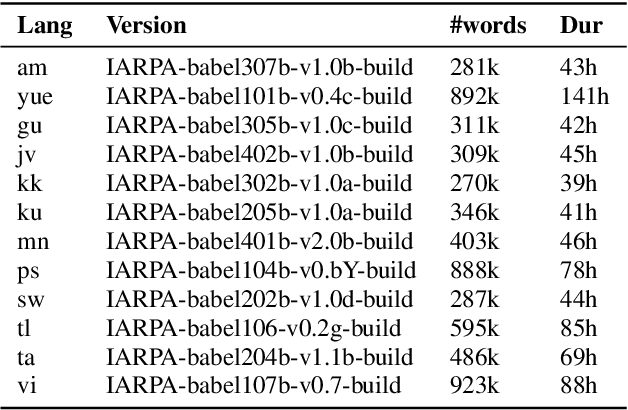
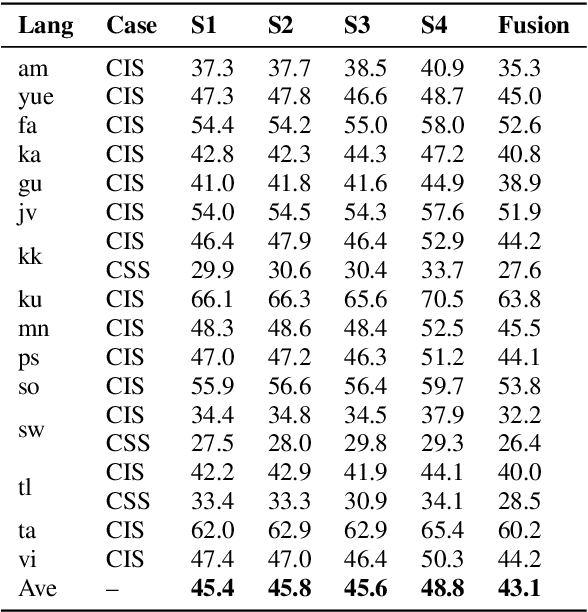
This paper describes the THUEE team's speech recognition system for the IARPA Open Automatic Speech Recognition Challenge (OpenASR21), with further experiment explorations. We achieve outstanding results under both the Constrained and Constrained-plus training conditions. For the Constrained training condition, we construct our basic ASR system based on the standard hybrid architecture. To alleviate the Out-Of-Vocabulary (OOV) problem, we extend the pronunciation lexicon using Grapheme-to-Phoneme (G2P) techniques for both OOV and potential new words. Standard acoustic model structures such as CNN-TDNN-F and CNN-TDNN-F-A are adopted. In addition, multiple data augmentation techniques are applied. For the Constrained-plus training condition, we use the self-supervised learning framework wav2vec2.0. We experiment with various fine-tuning techniques with the Connectionist Temporal Classification (CTC) criterion on top of the publicly available pre-trained model XLSR-53. We find that the frontend feature extractor plays an important role when applying the wav2vec2.0 pre-trained model to the encoder-decoder based CTC/Attention ASR architecture. Extra improvements can be achieved by using the CTC model finetuned in the target language as the frontend feature extractor.