 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSumEval: Towards Unified, Fine-Grained, Multi-Dimensional Summarization Evaluation for LLMs
Paper and Code
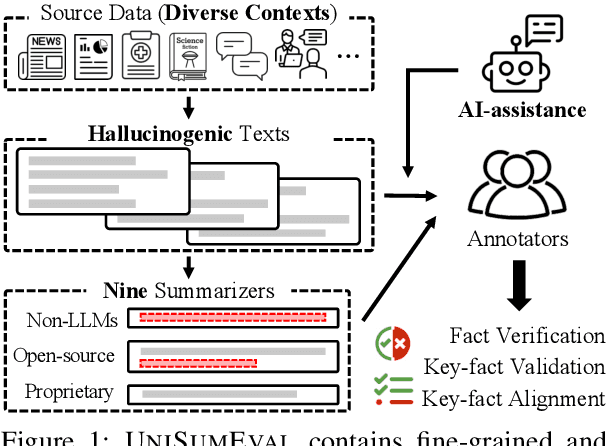
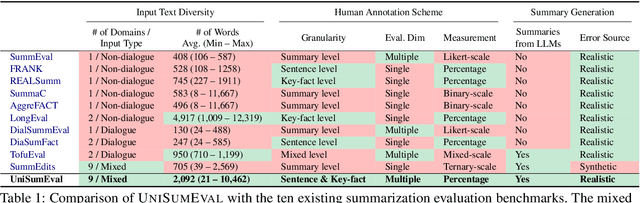
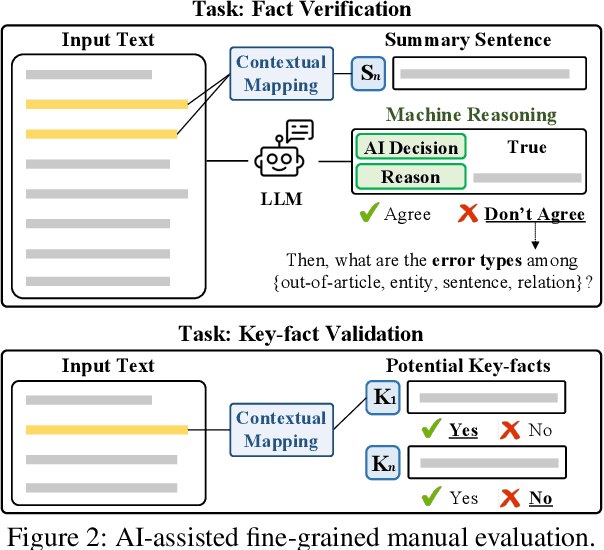

Existing benchmarks for summarization quality evaluation often lack diverse input scenarios, focus on narrowly defined dimensions (e.g., faithfulness), and struggle with subjective and coarse-grained annotation schemes. To address these shortcomings, we create UniSumEval benchmark, which extends the range of input context (e.g., domain, length) and provides fine-grained, multi-dimensional annotations. We use AI assistance in data creation, identifying potentially hallucinogenic input texts, and also helping human annotators reduce the difficulty of fine-grained annotation tasks. With UniSumEval, we benchmark nine latest language models as summarizers, offering insights into their performance across varying input contexts and evaluation dimensions. Furthermore, we conduct a thorough comparison of SOTA automated summary evaluators. Our benchmark data will be available at https://github.com/DISL-Lab/UniSumEval-v1.0.