 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Speaker Error Correction: Leveraging Language Models for Speaker Diarization Error Correction
Paper and Code
Jun 15, 2023
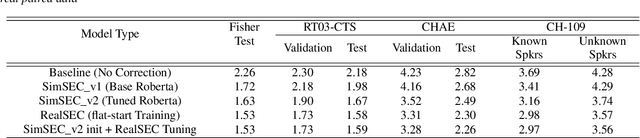
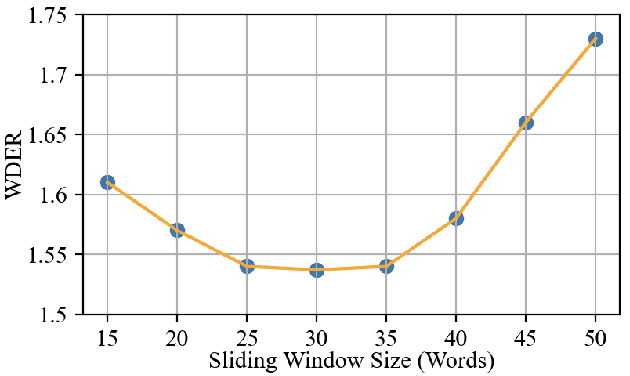
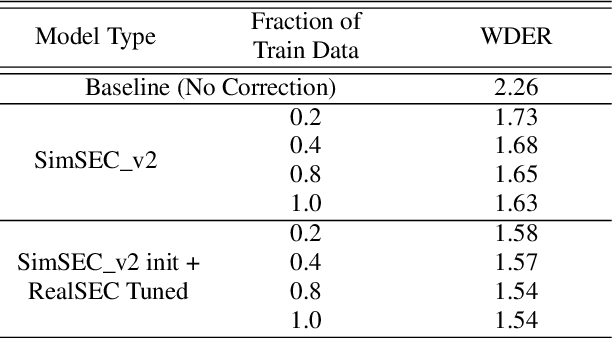
Speaker diarization (SD) is typically used with an automatic speech recognition (ASR) system to ascribe speaker labels to recognized words. The conventional approach reconciles outputs from independently optimized ASR and SD systems, where the SD system typically uses only acoustic information to identify the speakers in the audio stream. This approach can lead to speaker errors especially around speaker turns and regions of speaker overlap. In this paper, we propose a novel second-pass speaker error correction system using lexical information, leveraging the power of modern language models (LMs). Our experiments across multiple telephony datasets show that our approach is both effective and robust. Training and tuning only on the Fisher dataset, this error correction approach leads to relative word-level diarization error rate (WDER) reductions of 15-30% on three telephony datasets: RT03-CTS, Callhome American English and held-out portions of Fisher.