 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAG-LSEC: Audio Grounded Lexical Speaker Error Correction
Paper and Code
Jun 25, 2024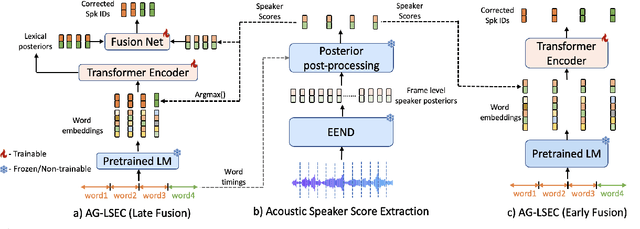

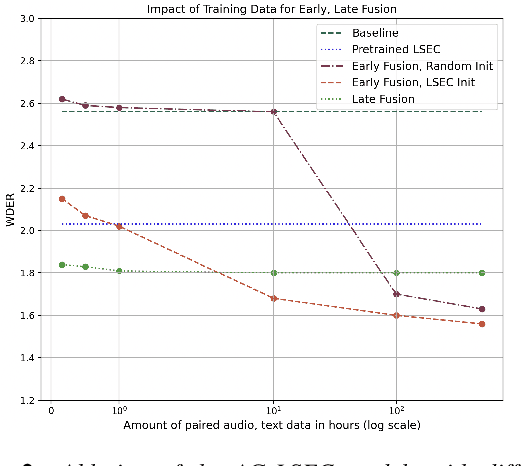
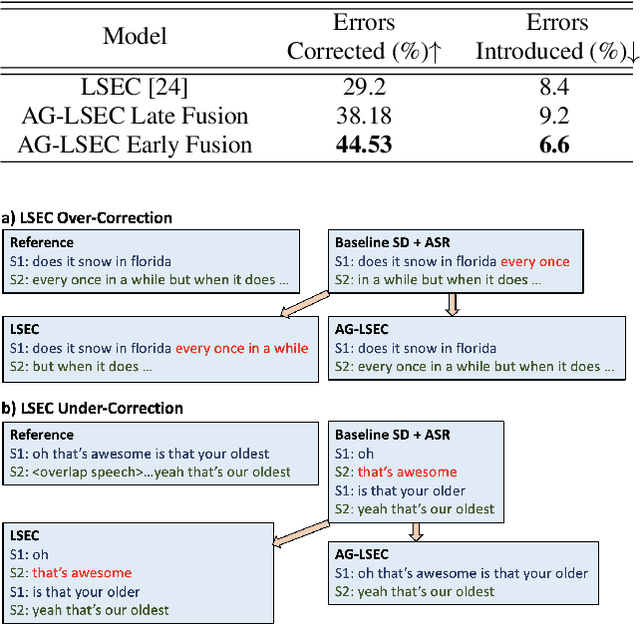
Speaker Diarization (SD) systems are typically audio-based and operate independently of the ASR system in traditional speech transcription pipelines and can have speaker errors due to SD and/or ASR reconciliation, especially around speaker turns and regions of speech overlap. To reduce these errors, a Lexical Speaker Error Correction (LSEC), in which an external language model provides lexical information to correct the speaker errors, was recently proposed. Though the approach achieves good Word Diarization error rate (WDER) improvements, it does not use any additional acoustic information and is prone to miscorrections. In this paper, we propose to enhance and acoustically ground the LSEC system with speaker scores directly derived from the existing SD pipeline. This approach achieves significant relative WDER reductions in the range of 25-40% over the audio-based SD, ASR system and beats the LSEC system by 15-25% relative on RT03-CTS, Callhome American English and Fisher datasets.