 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEQUATOR: A Deterministic Framework for Evaluating LLM Reasoning with Open-Ended Questions. # v1.0.0-beta
Dec 31, 2024Despite the remarkable coherence of Large Language Models (LLMs), existing evaluation methods often suffer from fluency bias and rely heavily on multiple-choice formats, making it difficult to assess factual accuracy and complex reasoning effectively. LLMs thus frequently generate factually inaccurate responses, especially in complex reasoning tasks, highlighting two prominent challenges: (1) the inadequacy of existing methods to evaluate reasoning and factual accuracy effectively, and (2) the reliance on human evaluators for nuanced judgment, as illustrated by Williams and Huckle (2024)[1], who found manual grading indispensable despite automated grading advancements. To address evaluation gaps in open-ended reasoning tasks, we introduce the EQUATOR Evaluator (Evaluation of Question Answering Thoroughness in Open-ended Reasoning). This framework combines deterministic scoring with a focus on factual accuracy and robust reasoning assessment. Using a vector database, EQUATOR pairs open-ended questions with human-evaluated answers, enabling more precise and scalable evaluations. In practice, EQUATOR significantly reduces reliance on human evaluators for scoring and improves scalability compared to Williams and Huckle's (2004)[1] methods. Our results demonstrate that this framework significantly outperforms traditional multiple-choice evaluations while maintaining high accuracy standards. Additionally, we introduce an automated evaluation process leveraging smaller, locally hosted LLMs. We used LLaMA 3.2B, running on the Ollama binaries to streamline our assessments. This work establishes a new paradigm for evaluating LLM performance, emphasizing factual accuracy and reasoning ability, and provides a robust methodological foundation for future research.
Enhanced Momentum with Momentum Transformers
Dec 17, 2024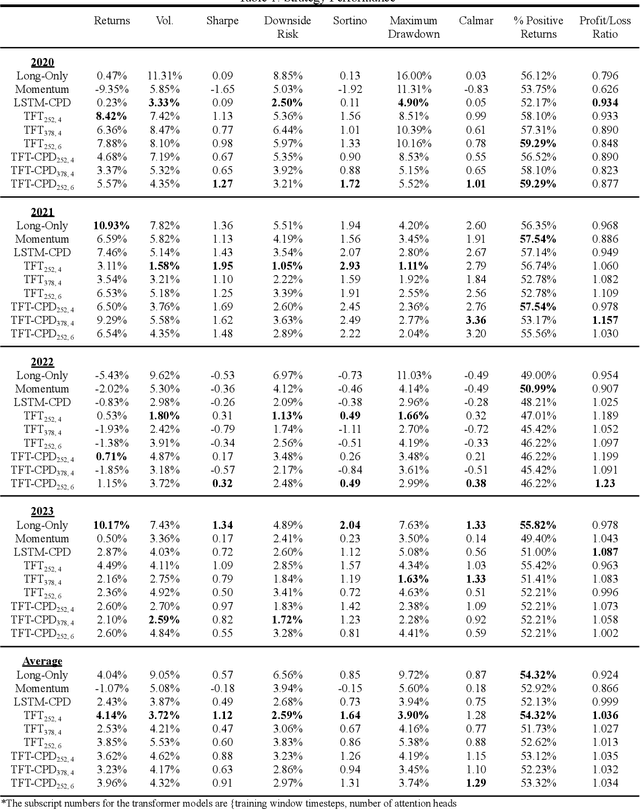
The primary objective of this research is to build a Momentum Transformer that is expected to outperform benchmark time-series momentum and mean-reversion trading strategies. We extend the ideas introduced in the paper Trading with the Momentum Transformer: An Intelligent and Interpretable Architecture to equities as the original paper primarily only builds upon futures and equity indices. Unlike conventional Long Short-Term Memory (LSTM) models, which operate sequentially and are optimized for processing local patterns, an attention mechanism equips our architecture with direct access to all prior time steps in the training window. This hybrid design, combining attention with an LSTM, enables the model to capture long-term dependencies, enhance performance in scenarios accounting for transaction costs, and seamlessly adapt to evolving market conditions, such as those witnessed during the Covid Pandemic. We average 4.14% returns which is similar to the original papers results. Our Sharpe is lower at an average of 1.12 due to much higher volatility which may be due to stocks being inherently more volatile than futures and indices.