 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
Paper and Code

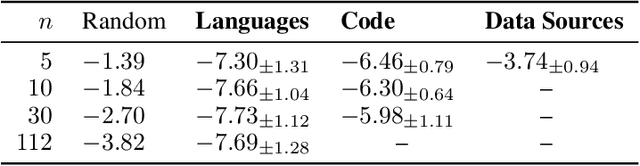
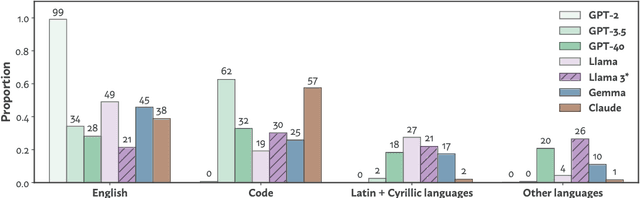

The pretraining data of today's strongest language models is opaque; in particular, little is known about the proportions of various domains or languages represented. In this work, we tackle a task which we call data mixture inference, which aims to uncover the distributional make-up of training data. We introduce a novel attack based on a previously overlooked source of information -- byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models. Our key insight is that the ordered list of merge rules learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data: the first merge is the most common byte pair, the second is the most common pair after merging the first token, and so on. Given a tokenizer's merge list along with data samples for each category of interest, we formulate a linear program that solves for the proportion of each category in the tokenizer's training set. Importantly, to the extent to which tokenizer training data is representative of the pretraining data, we indirectly learn about pretraining data. In controlled experiments, we show that our attack recovers mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources. We then apply our approach to off-the-shelf tokenizers released with recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o's tokenizer is much more multilingual than its predecessors, training on 39% non-English data; Llama3 extends GPT-3.5's tokenizer primarily for multilingual (48%) use; GPT-3.5's and Claude's tokenizers are trained on predominantly code (~60%). We hope our work sheds light on current design practices for pretraining data, and inspires continued research into data mixture inference for LMs.