 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-$K$ Ranking from Pairwise Comparisons: When Spectral Ranking is Optimal
Paper and Code
Mar 14, 2016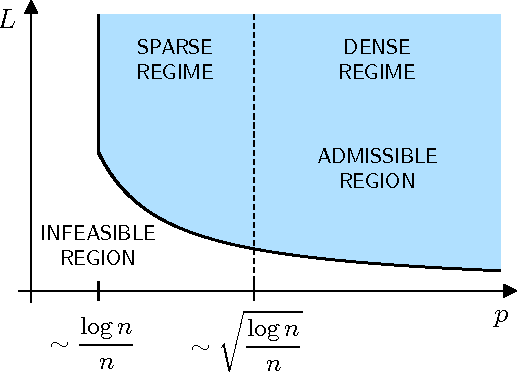
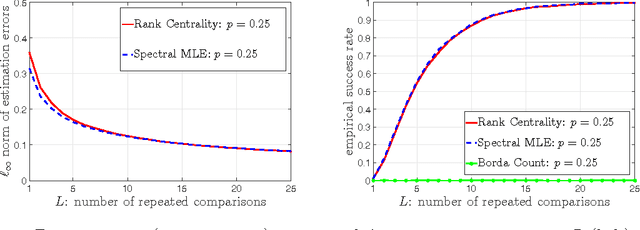
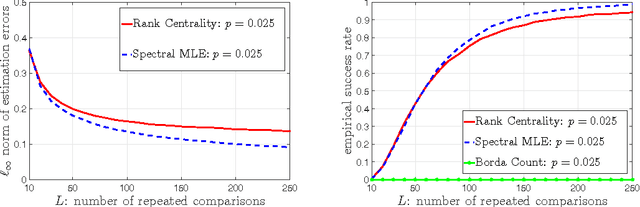
We explore the top-$K$ rank aggregation problem. Suppose a collection of items is compared in pairs repeatedly, and we aim to recover a consistent ordering that focuses on the top-$K$ ranked items based on partially revealed preference information. We investigate the Bradley-Terry-Luce model in which one ranks items according to their perceived utilities modeled as noisy observations of their underlying true utilities. Our main contributions are two-fold. First, in a general comparison model where item pairs to compare are given a priori, we attain an upper and lower bound on the sample size for reliable recovery of the top-$K$ ranked items. Second, more importantly, extending the result to a random comparison model where item pairs to compare are chosen independently with some probability, we show that in slightly restricted regimes, the gap between the derived bounds reduces to a constant factor, hence reveals that a spectral method can achieve the minimax optimality on the (order-wise) sample size required for top-$K$ ranking. That is to say, we demonstrate a spectral method alone to be sufficient to achieve the optimality and advantageous in terms of computational complexity, as it does not require an additional stage of maximum likelihood estimation that a state-of-the-art scheme employs to achieve the optimality. We corroborate our main results by numerical experiments.