 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Guide for KOTE: Korean Online Comments Emotions Dataset
Paper and Code

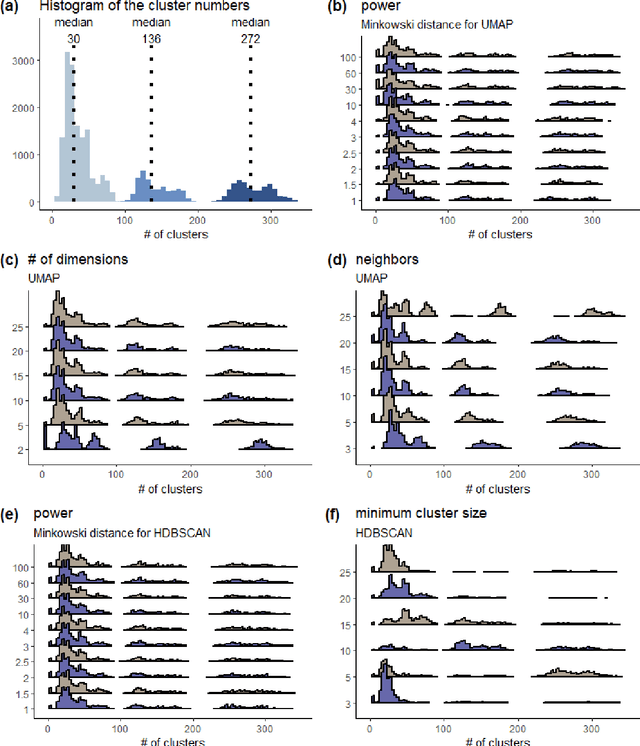
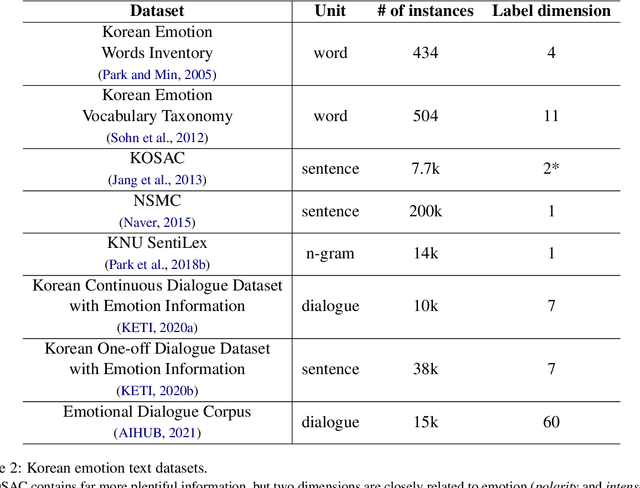
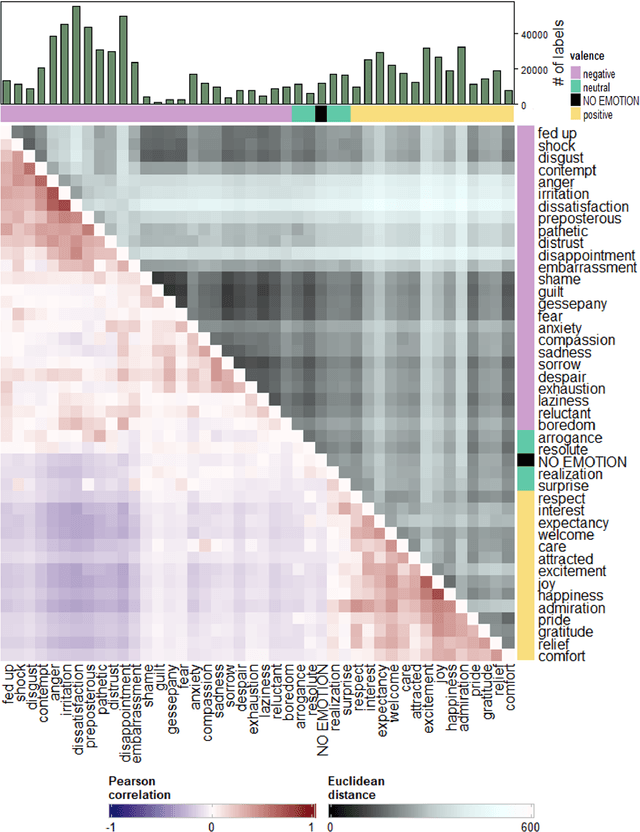
Sentiment analysis that classifies data into positive or negative has been dominantly used to recognize emotional aspects of texts, despite the deficit of thorough examination of emotional meanings. Recently, corpora labeled with more than just valence are built to exceed this limit. However, most Korean emotion corpora are small in the number of instances and cover a limited range of emotions. We introduce KOTE dataset. KOTE contains 50k (250k cases) Korean online comments, each of which is manually labeled for 43 emotion labels or one special label (NO EMOTION) by crowdsourcing (Ps = 3,048). The emotion taxonomy of the 43 emotions is systematically established by cluster analysis of Korean emotion concepts expressed on word embedding space. After explaining how KOTE is developed, we also discuss the results of finetuning and analysis for social discrimination in the corpus.