 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATSBI: Generative Agent-centric Spatio-temporal Object Interaction
Paper and Code

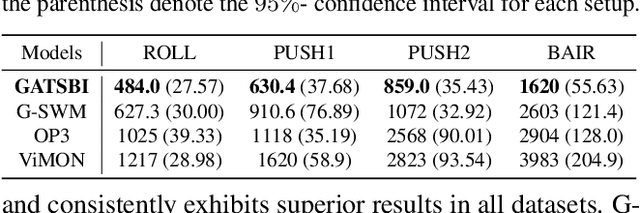
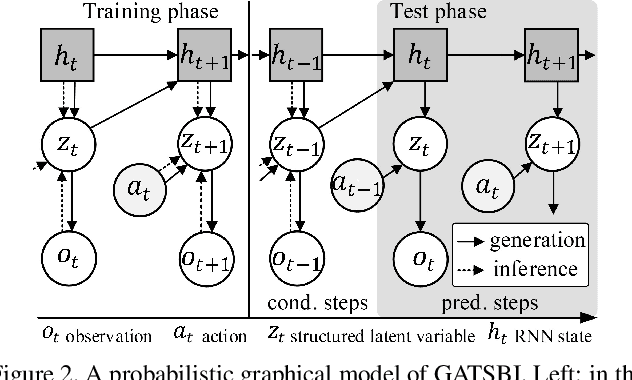
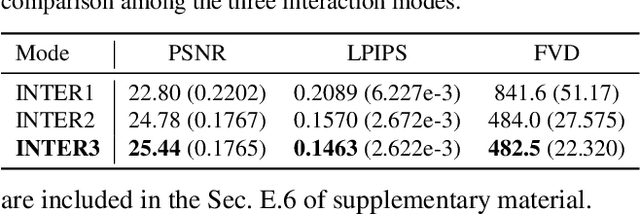
We present GATSBI, a generative model that can transform a sequence of raw observations into a structured latent representation that fully captures the spatio-temporal context of the agent's actions. In vision-based decision-making scenarios, an agent faces complex high-dimensional observations where multiple entities interact with each other. The agent requires a good scene representation of the visual observation that discerns essential components and consistently propagates along the time horizon. Our method, GATSBI, utilizes unsupervised object-centric scene representation learning to separate an active agent, static background, and passive objects. GATSBI then models the interactions reflecting the causal relationships among decomposed entities and predicts physically plausible future states. Our model generalizes to a variety of environments where different types of robots and objects dynamically interact with each other. We show GATSBI achieves superior performance on scene decomposition and video prediction compared to its state-of-the-art counterparts.