 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowPlan-G2P: A Structured Generation Framework for Transforming Scientific Papers into Patent Descriptions
Jan 05, 2026Over 3.5 million patents are filed annually, with drafting patent descriptions requiring deep technical and legal expertise. Transforming scientific papers into patent descriptions is particularly challenging due to their differing rhetorical styles and stringent legal requirements. Unlike black-box text-to-text approaches that struggle to model structural reasoning and legal constraints, we propose FlowPlan-G2P, a novel framework that mirrors the cognitive workflow of expert drafters by reformulating this task into three stages: (1) Concept Graph Induction, extracting technical entities and relationships into a directed graph via expert-like reasoning; (2) Paragraph and Section Planning, reorganizing the graph into coherent clusters aligned with canonical patent sections; and (3) Graph-Conditioned Generation, producing legally compliant paragraphs using section-specific subgraphs and tailored prompts. Experiments demonstrate that FlowPlan-G2P significantly improves logical coherence and legal compliance over end-to-end LLM baselines. Our framework establishes a new paradigm for paper-to-patent generation and advances structured text generation for specialized domains.
Pat-DEVAL: Chain-of-Legal-Thought Evaluation for Patent Description
Jan 01, 2026Patent descriptions must deliver comprehensive technical disclosure while meeting strict legal standards such as enablement and written description requirements. Although large language models have enabled end-to-end automated patent drafting, existing evaluation approaches fail to assess long-form structural coherence and statutory compliance specific to descriptions. We propose Pat-DEVAL, the first multi-dimensional evaluation framework dedicated to patent description bodies. Leveraging the LLM-as-a-judge paradigm, Pat-DEVAL introduces Chain-of-Legal-Thought (CoLT), a legally-constrained reasoning mechanism that enforces sequential patent-law-specific analysis. Experiments validated by patent expert on our Pap2Pat-EvalGold dataset demonstrate that Pat-DEVAL achieves a Pearson correlation of 0.69, significantly outperforming baseline metrics and existing LLM evaluators. Notably, the framework exhibits a superior correlation of 0.73 in Legal-Professional Compliance, proving that the explicit injection of statutory constraints is essential for capturing nuanced legal validity. By establishing a new standard for ensuring both technical soundness and legal compliance, Pat-DEVAL provides a robust methodological foundation for the practical deployment of automated patent drafting systems.
PatentScore: Multi-dimensional Evaluation of LLM-Generated Patent Claims
May 25, 2025Natural language generation (NLG) metrics play a central role in evaluating generated texts, but are not well suited for the structural and legal characteristics of patent documents. Large language models (LLMs) offer strong potential in automating patent generation, yet research on evaluating LLM-generated patents remains limited, especially in evaluating the generation quality of patent claims, which are central to defining the scope of protection. Effective claim evaluation requires addressing legal validity, technical accuracy, and structural compliance. To address this gap, we introduce PatentScore, a multi-dimensional evaluation framework for assessing LLM-generated patent claims. PatentScore incorporates: (1) hierarchical decomposition for claim analysis; (2) domain-specific validation patterns based on legal and technical standards; and (3) scoring across structural, semantic, and legal dimensions. Unlike general-purpose NLG metrics, PatentScore reflects patent-specific constraints and document structures, enabling evaluation beyond surface similarity. We evaluate 400 GPT-4o-mini generated Claim 1s and report a Pearson correlation of $r = 0.819$ with expert annotations, outperforming existing NLG metrics. Furthermore, we conduct additional evaluations using open models such as Claude-3.5-Haiku and Gemini-1.5-flash, all of which show strong correlations with expert judgments, confirming the robustness and generalizability of our framework.
PatentMind: A Multi-Aspect Reasoning Graph for Patent Similarity Evaluation
May 25, 2025Patent similarity evaluation plays a critical role in intellectual property analysis. However, existing methods often overlook the intricate structure of patent documents, which integrate technical specifications, legal boundaries, and application contexts. We introduce PatentMind, a novel framework for patent similarity assessment based on a Multi-Aspect Reasoning Graph (MARG). PatentMind decomposes patents into three core dimensions: technical feature, application domain, and claim scope, to compute dimension-specific similarity scores. These scores are dynamically weighted through a four-stage reasoning process which integrates contextual signals to emulate expert-level judgment. To support evaluation, we construct PatentSimBench, a human-annotated benchmark comprising 500 patent pairs. Experimental results demonstrate that PatentMind achieves a strong correlation ($r=0.938$) with expert annotations, significantly outperforming embedding-based models and advanced prompt engineering methods.These results highlight the effectiveness of modular reasoning frameworks in overcoming key limitations of embedding-based methods for analyzing patent similarity.
A Novel Patent Similarity Measurement Methodology: Semantic Distance and Technological Distance
Mar 23, 2023



Measuring similarity between patents is an essential step to ensure novelty of innovation. However, a large number of methods of measuring the similarity between patents still rely on manual classification of patents by experts. Another body of research has proposed automated methods; nevertheless, most of it solely focuses on the semantic similarity of patents. In order to tackle these limitations, we propose a hybrid method for automatically measuring the similarity between patents, considering both semantic and technological similarities. We measure the semantic similarity based on patent texts using BERT, calculate the technological similarity with IPC codes using Jaccard similarity, and perform hybridization by assigning weights to the two similarity methods. Our evaluation result demonstrates that the proposed method outperforms the baseline that considers the semantic similarity only.
Multi label classification of Artificial Intelligence related patents using Modified D2SBERT and Sentence Attention mechanism
Mar 03, 2023



Patent classification is an essential task in patent information management and patent knowledge mining. It is very important to classify patents related to artificial intelligence, which is the biggest topic these days. However, artificial intelligence-related patents are very difficult to classify because it is a mixture of complex technologies and legal terms. Moreover, due to the unsatisfactory performance of current algorithms, it is still mostly done manually, wasting a lot of time and money. Therefore, we present a method for classifying artificial intelligence-related patents published by the USPTO using natural language processing technique and deep learning methodology. We use deformed BERT and sentence attention overcome the limitations of BERT. Our experiment result is highest performance compared to other deep learning methods.
5-Star Hotel Customer Satisfaction Analysis Using Hybrid Methodology
Sep 26, 2022



Due to the rapid development of non-face-to-face services due to the corona virus, commerce through the Internet, such as sales and reservations, is increasing very rapidly. Consumers also post reviews, suggestions, or judgments about goods or services on the website. The review data directly used by consumers provides positive feedback and nice impact to consumers, such as creating business value. Therefore, analysing review data is very important from a marketing point of view. Our research suggests a new way to find factors for customer satisfaction through review data. We applied a method to find factors for customer satisfaction by mixing and using the data mining technique, which is a big data analysis method, and the natural language processing technique, which is a language processing method, in our research. Unlike many studies on customer satisfaction that have been conducted in the past, our research has a novelty of the thesis by using various techniques. And as a result of the analysis, the results of our experiments were very accurate.
DAGAM: Data Augmentation with Generation And Modification
Apr 06, 2022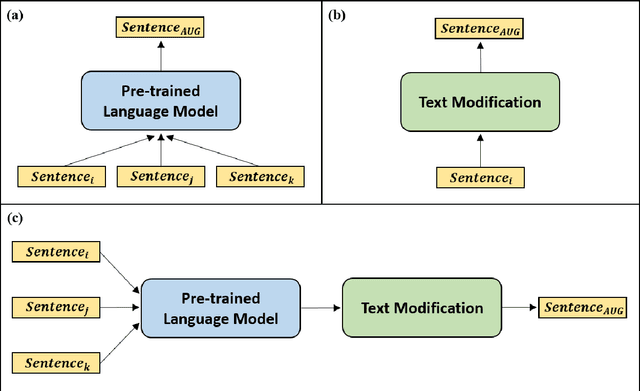
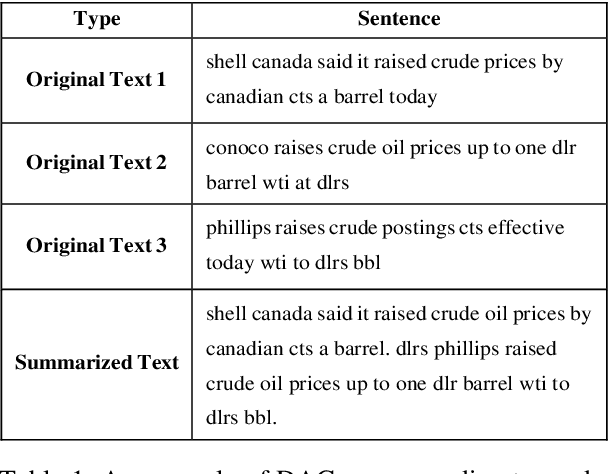

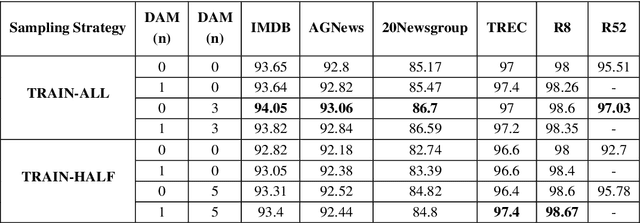
Text classification is a representative downstream task of natural language processing, and has exhibited excellent performance since the advent of pre-trained language models based on Transformer architecture. However, in pre-trained language models, under-fitting often occurs due to the size of the model being very large compared to the amount of available training data. Along with significant importance of data collection in modern machine learning paradigm, studies have been actively conducted for natural language data augmentation. In light of this, we introduce three data augmentation schemes that help reduce underfitting problems of large-scale language models. Primarily we use a generation model for data augmentation, which is defined as Data Augmentation with Generation (DAG). Next, we augment data using text modification techniques such as corruption and word order change (Data Augmentation with Modification, DAM). Finally, we propose Data Augmentation with Generation And Modification (DAGAM), which combines DAG and DAM techniques for a boosted performance. We conduct data augmentation for six benchmark datasets of text classification task, and verify the usefulness of DAG, DAM, and DAGAM through BERT-based fine-tuning and evaluation, deriving better results compared to the performance with original datasets.
Artificial Intelligence Technology analysis using Artificial Intelligence patent through Deep Learning model and vector space model
Nov 08, 2021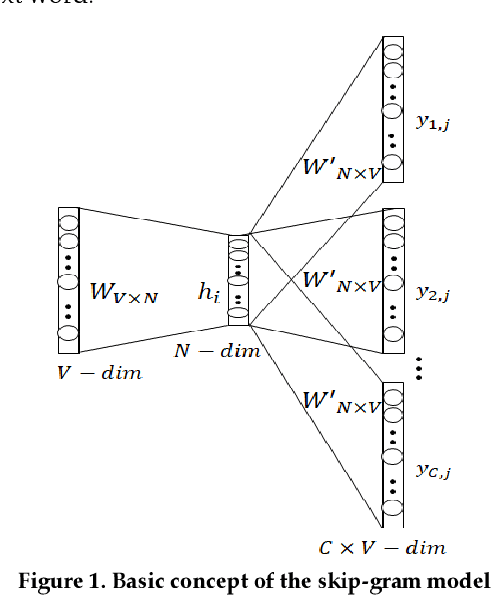
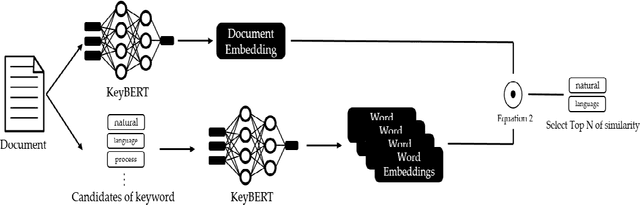

Thanks to rapid development of artificial intelligence technology in recent years, the current artificial intelligence technology is contributing to many part of society. Education, environment, medical care, military, tourism, economy, politics, etc. are having a very large impact on society as a whole. For example, in the field of education, there is an artificial intelligence tutoring system that automatically assigns tutors based on student's level. In the field of economics, there are quantitative investment methods that automatically analyze large amounts of data to find investment laws to create investment models or predict changes in financial markets. As such, artificial intelligence technology is being used in various fields. So, it is very important to know exactly what factors have an important influence on each field of artificial intelligence technology and how the relationship between each field is connected. Therefore, it is necessary to analyze artificial intelligence technology in each field. In this paper, we analyze patent documents related to artificial intelligence technology. We propose a method for keyword analysis within factors using artificial intelligence patent data sets for artificial intelligence technology analysis. This is a model that relies on feature engineering based on deep learning model named KeyBERT, and using vector space model. A case study of collecting and analyzing artificial intelligence patent data was conducted to show how the proposed model can be applied to real world problems.
Solar cell patent classification method based on keyword extraction and deep neural network
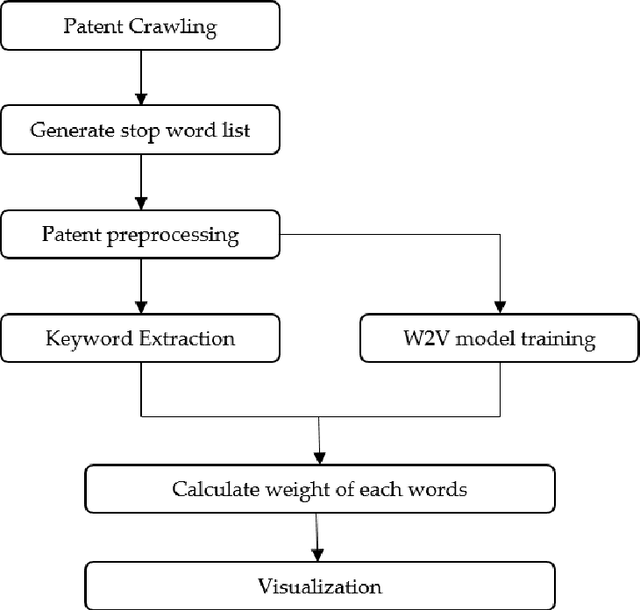
Sep 18, 2021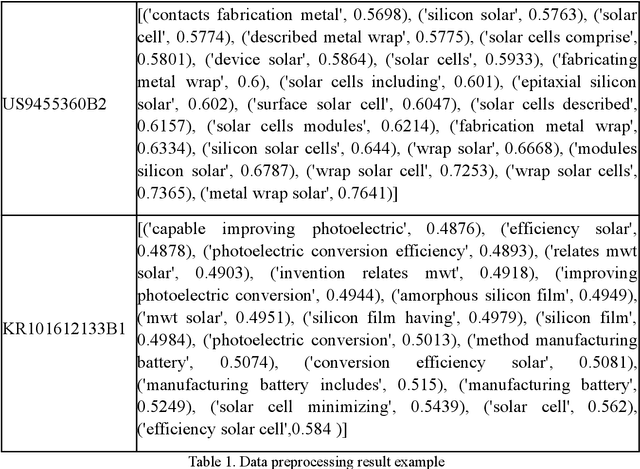
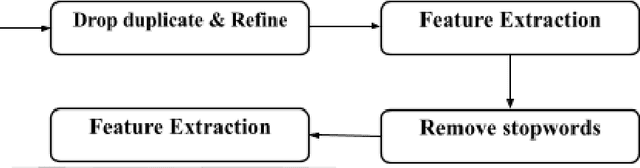
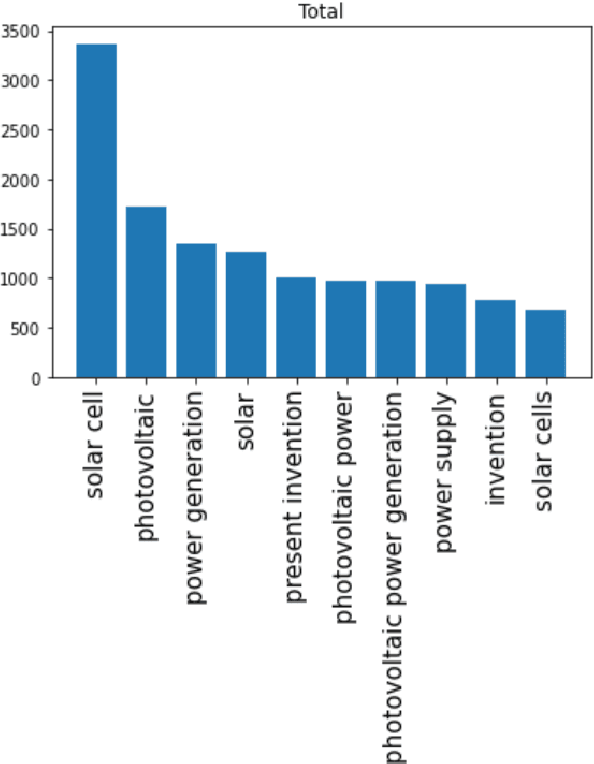
With the growing impact of ESG on businesses, research related to renewable energy is receiving great attention. Solar cells are one of them, and accordingly, it can be said that the research value of solar cell patent analysis is very high. Patent documents have high research value. Being able to accurately analyze and classify patent documents can reveal several important technical relationships. It can also describe the business trends in that technology. And when it comes to investment, new industrial solutions will also be inspired and proposed to make important decisions. Therefore, we must carefully analyze patent documents and utilize the value of patents. To solve the solar cell patent classification problem, we propose a keyword extraction method and a deep neural network-based solar cell patent classification method. First, solar cell patents are analyzed for pretreatment. It then uses the KeyBERT algorithm to extract keywords and key phrases from the patent abstract to construct a lexical dictionary. We then build a solar cell patent classification model according to the deep neural network. Finally, we use a deep neural network-based solar cell patent classification model to classify power patents, and the training accuracy is greater than 95%. Also, the validation accuracy is about 87.5%. It can be seen that the deep neural network method can not only realize the classification of complex and difficult solar cell patents, but also have a good classification effect.