 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowPlan-G2P: A Structured Generation Framework for Transforming Scientific Papers into Patent Descriptions
Jan 05, 2026Over 3.5 million patents are filed annually, with drafting patent descriptions requiring deep technical and legal expertise. Transforming scientific papers into patent descriptions is particularly challenging due to their differing rhetorical styles and stringent legal requirements. Unlike black-box text-to-text approaches that struggle to model structural reasoning and legal constraints, we propose FlowPlan-G2P, a novel framework that mirrors the cognitive workflow of expert drafters by reformulating this task into three stages: (1) Concept Graph Induction, extracting technical entities and relationships into a directed graph via expert-like reasoning; (2) Paragraph and Section Planning, reorganizing the graph into coherent clusters aligned with canonical patent sections; and (3) Graph-Conditioned Generation, producing legally compliant paragraphs using section-specific subgraphs and tailored prompts. Experiments demonstrate that FlowPlan-G2P significantly improves logical coherence and legal compliance over end-to-end LLM baselines. Our framework establishes a new paradigm for paper-to-patent generation and advances structured text generation for specialized domains.
Pat-DEVAL: Chain-of-Legal-Thought Evaluation for Patent Description
Jan 01, 2026Patent descriptions must deliver comprehensive technical disclosure while meeting strict legal standards such as enablement and written description requirements. Although large language models have enabled end-to-end automated patent drafting, existing evaluation approaches fail to assess long-form structural coherence and statutory compliance specific to descriptions. We propose Pat-DEVAL, the first multi-dimensional evaluation framework dedicated to patent description bodies. Leveraging the LLM-as-a-judge paradigm, Pat-DEVAL introduces Chain-of-Legal-Thought (CoLT), a legally-constrained reasoning mechanism that enforces sequential patent-law-specific analysis. Experiments validated by patent expert on our Pap2Pat-EvalGold dataset demonstrate that Pat-DEVAL achieves a Pearson correlation of 0.69, significantly outperforming baseline metrics and existing LLM evaluators. Notably, the framework exhibits a superior correlation of 0.73 in Legal-Professional Compliance, proving that the explicit injection of statutory constraints is essential for capturing nuanced legal validity. By establishing a new standard for ensuring both technical soundness and legal compliance, Pat-DEVAL provides a robust methodological foundation for the practical deployment of automated patent drafting systems.
SK-VQA: Synthetic Knowledge Generation at Scale for Training Context-Augmented Multimodal LLMs
Jun 28, 2024
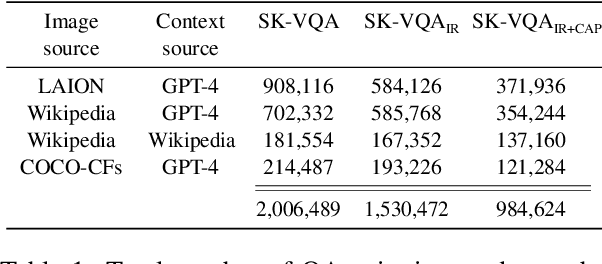


Synthetic data generation has gained significant attention recently for its utility in training large vision and language models. However, the application of synthetic data to the training of multimodal context-augmented generation systems has been relatively unexplored. This gap in existing work is important because existing vision and language models (VLMs) are not trained specifically for context-augmented generation. Resources for adapting such models are therefore crucial for enabling their use in retrieval-augmented generation (RAG) settings, where a retriever is used to gather relevant information that is then subsequently provided to a generative model via context augmentation. To address this challenging problem, we generate SK-VQA: a large synthetic multimodal dataset containing over 2 million question-answer pairs which require external knowledge to determine the final answer. Our dataset is both larger and significantly more diverse than existing resources of its kind, possessing over 11x more unique questions and containing images from a greater variety of sources than previously-proposed datasets. Through extensive experiments, we demonstrate that our synthetic dataset can not only serve as a challenging benchmark, but is also highly effective for adapting existing generative multimodal models for context-augmented generation.