 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSK-VQA: Synthetic Knowledge Generation at Scale for Training Context-Augmented Multimodal LLMs
Paper and Code

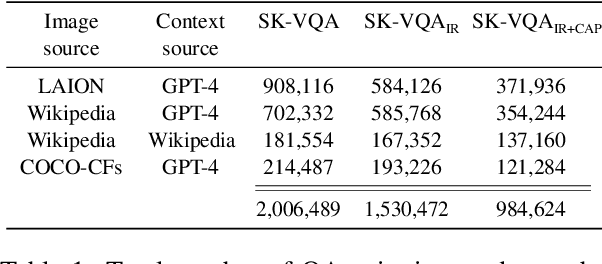


Synthetic data generation has gained significant attention recently for its utility in training large vision and language models. However, the application of synthetic data to the training of multimodal context-augmented generation systems has been relatively unexplored. This gap in existing work is important because existing vision and language models (VLMs) are not trained specifically for context-augmented generation. Resources for adapting such models are therefore crucial for enabling their use in retrieval-augmented generation (RAG) settings, where a retriever is used to gather relevant information that is then subsequently provided to a generative model via context augmentation. To address this challenging problem, we generate SK-VQA: a large synthetic multimodal dataset containing over 2 million question-answer pairs which require external knowledge to determine the final answer. Our dataset is both larger and significantly more diverse than existing resources of its kind, possessing over 11x more unique questions and containing images from a greater variety of sources than previously-proposed datasets. Through extensive experiments, we demonstrate that our synthetic dataset can not only serve as a challenging benchmark, but is also highly effective for adapting existing generative multimodal models for context-augmented generation.