 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5-Star Hotel Customer Satisfaction Analysis Using Hybrid Methodology
Sep 26, 2022



Due to the rapid development of non-face-to-face services due to the corona virus, commerce through the Internet, such as sales and reservations, is increasing very rapidly. Consumers also post reviews, suggestions, or judgments about goods or services on the website. The review data directly used by consumers provides positive feedback and nice impact to consumers, such as creating business value. Therefore, analysing review data is very important from a marketing point of view. Our research suggests a new way to find factors for customer satisfaction through review data. We applied a method to find factors for customer satisfaction by mixing and using the data mining technique, which is a big data analysis method, and the natural language processing technique, which is a language processing method, in our research. Unlike many studies on customer satisfaction that have been conducted in the past, our research has a novelty of the thesis by using various techniques. And as a result of the analysis, the results of our experiments were very accurate.
DAGAM: Data Augmentation with Generation And Modification
Apr 06, 2022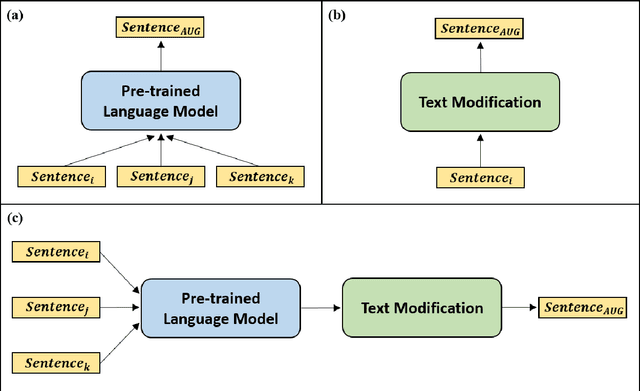
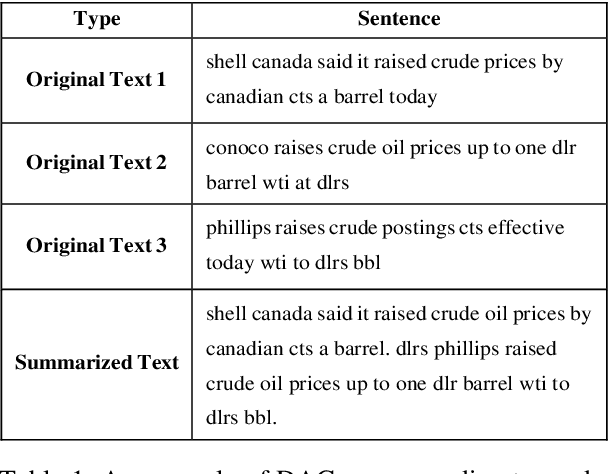

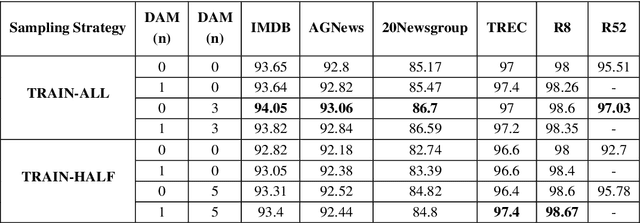
Text classification is a representative downstream task of natural language processing, and has exhibited excellent performance since the advent of pre-trained language models based on Transformer architecture. However, in pre-trained language models, under-fitting often occurs due to the size of the model being very large compared to the amount of available training data. Along with significant importance of data collection in modern machine learning paradigm, studies have been actively conducted for natural language data augmentation. In light of this, we introduce three data augmentation schemes that help reduce underfitting problems of large-scale language models. Primarily we use a generation model for data augmentation, which is defined as Data Augmentation with Generation (DAG). Next, we augment data using text modification techniques such as corruption and word order change (Data Augmentation with Modification, DAM). Finally, we propose Data Augmentation with Generation And Modification (DAGAM), which combines DAG and DAM techniques for a boosted performance. We conduct data augmentation for six benchmark datasets of text classification task, and verify the usefulness of DAG, DAM, and DAGAM through BERT-based fine-tuning and evaluation, deriving better results compared to the performance with original datasets.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jul 05, 2021
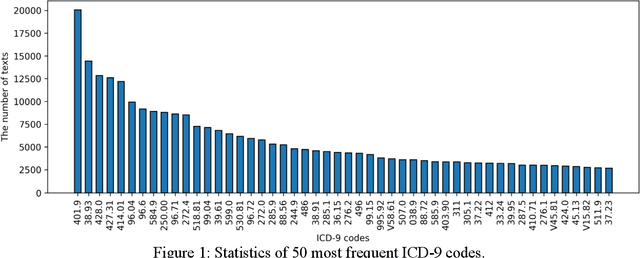
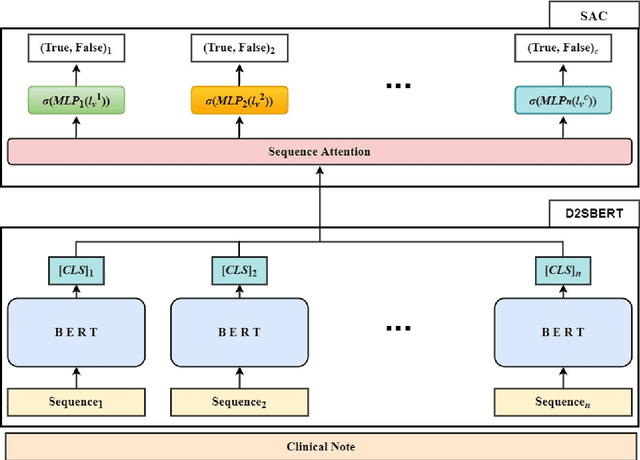

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the International Classification of Diseases(ICD). ICD code is an important code used in various operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformers (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our approach on the medical information mart for intensive care III (MIMIC-III) benchmark dataset. Our model achieved performance of macro-averaged F1: 0.62898 and micro-averaged F1: 0.68555 and is performing better than a performance of the state-of-the-art model using the MIMIC-III dataset. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture important sequence in-formation appearing in documents.
A novel hybrid methodology of measuring sentence similarity
May 20, 2021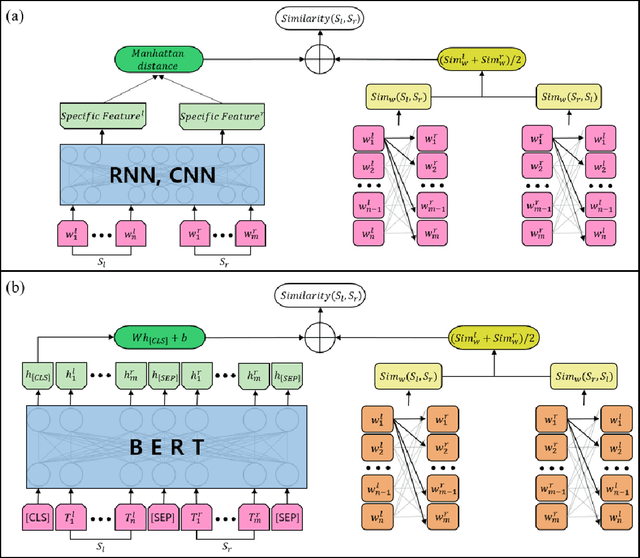

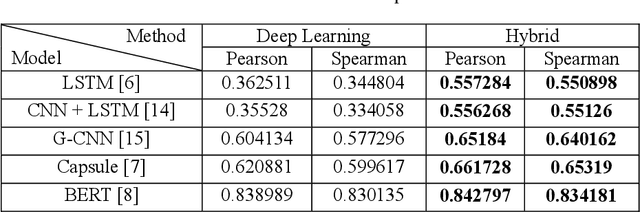
The problem of measuring sentence similarity is an essential issue in the natural language processing (NLP) area. It is necessary to measure the similarity between sentences accurately. There are many approaches to measuring sentence similarity. Deep learning methodology shows a state-of-the-art performance in many natural language processing fields and is used a lot in sentence similarity measurement methods. However, in the natural language processing field, considering the structure of the sentence or the word structure that makes up the sentence is also important. In this study, we propose a methodology combined with both deep learning methodology and a method considering lexical relationships. Our evaluation metric is the Pearson correlation coefficient and Spearman correlation coefficient. As a result, the proposed method outperforms the current approaches on a KorSTS standard benchmark Korean dataset. Moreover, it performs a maximum of 65% increase than only using deep learning methodology. Experiments show that our proposed method generally results in better performance than those with only a deep learning model.