 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGAM: Data Augmentation with Generation And Modification
Apr 06, 2022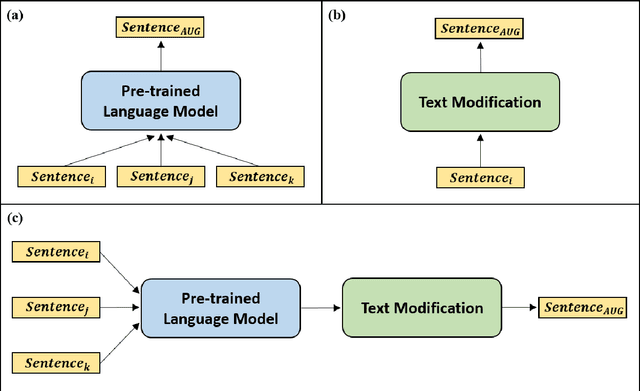
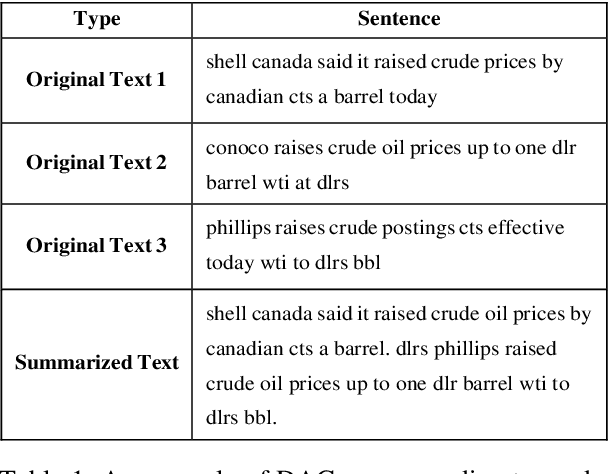

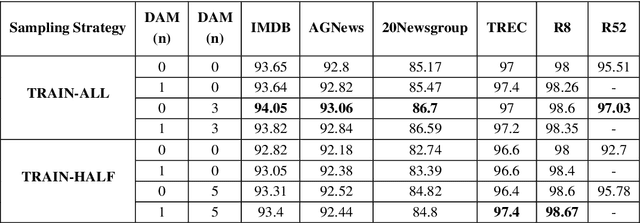
Text classification is a representative downstream task of natural language processing, and has exhibited excellent performance since the advent of pre-trained language models based on Transformer architecture. However, in pre-trained language models, under-fitting often occurs due to the size of the model being very large compared to the amount of available training data. Along with significant importance of data collection in modern machine learning paradigm, studies have been actively conducted for natural language data augmentation. In light of this, we introduce three data augmentation schemes that help reduce underfitting problems of large-scale language models. Primarily we use a generation model for data augmentation, which is defined as Data Augmentation with Generation (DAG). Next, we augment data using text modification techniques such as corruption and word order change (Data Augmentation with Modification, DAM). Finally, we propose Data Augmentation with Generation And Modification (DAGAM), which combines DAG and DAM techniques for a boosted performance. We conduct data augmentation for six benchmark datasets of text classification task, and verify the usefulness of DAG, DAM, and DAGAM through BERT-based fine-tuning and evaluation, deriving better results compared to the performance with original datasets.
Artificial Intelligence Technology analysis using Artificial Intelligence patent through Deep Learning model and vector space model
Nov 08, 2021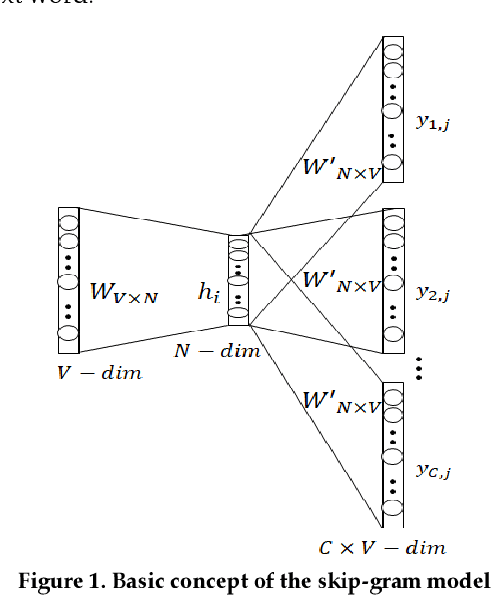
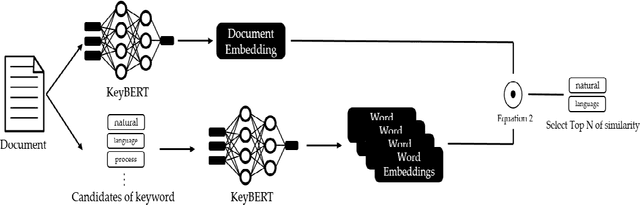

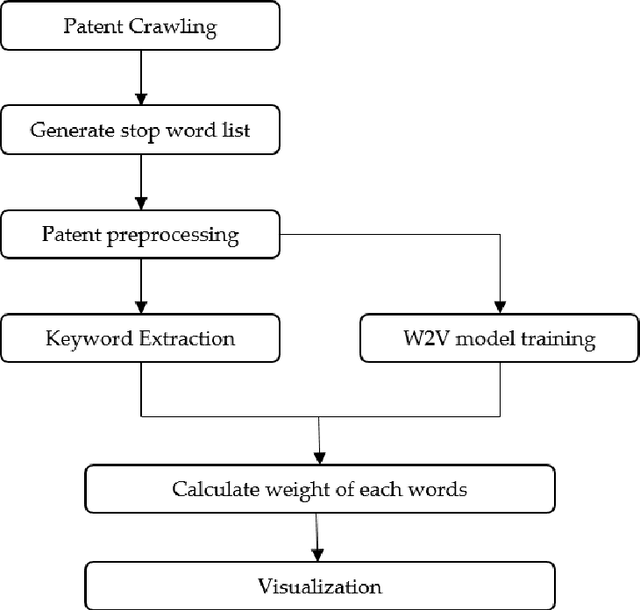
Thanks to rapid development of artificial intelligence technology in recent years, the current artificial intelligence technology is contributing to many part of society. Education, environment, medical care, military, tourism, economy, politics, etc. are having a very large impact on society as a whole. For example, in the field of education, there is an artificial intelligence tutoring system that automatically assigns tutors based on student's level. In the field of economics, there are quantitative investment methods that automatically analyze large amounts of data to find investment laws to create investment models or predict changes in financial markets. As such, artificial intelligence technology is being used in various fields. So, it is very important to know exactly what factors have an important influence on each field of artificial intelligence technology and how the relationship between each field is connected. Therefore, it is necessary to analyze artificial intelligence technology in each field. In this paper, we analyze patent documents related to artificial intelligence technology. We propose a method for keyword analysis within factors using artificial intelligence patent data sets for artificial intelligence technology analysis. This is a model that relies on feature engineering based on deep learning model named KeyBERT, and using vector space model. A case study of collecting and analyzing artificial intelligence patent data was conducted to show how the proposed model can be applied to real world problems.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jul 05, 2021
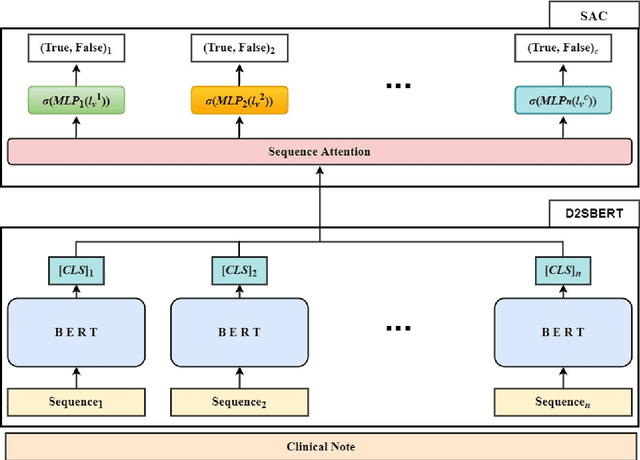

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the International Classification of Diseases(ICD). ICD code is an important code used in various operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformers (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our approach on the medical information mart for intensive care III (MIMIC-III) benchmark dataset. Our model achieved performance of macro-averaged F1: 0.62898 and micro-averaged F1: 0.68555 and is performing better than a performance of the state-of-the-art model using the MIMIC-III dataset. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture important sequence in-formation appearing in documents.