 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel hybrid methodology of measuring sentence similarity
Paper and Code
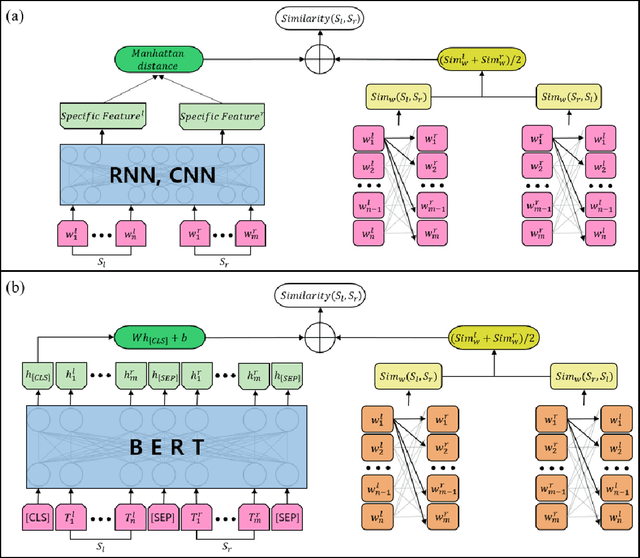

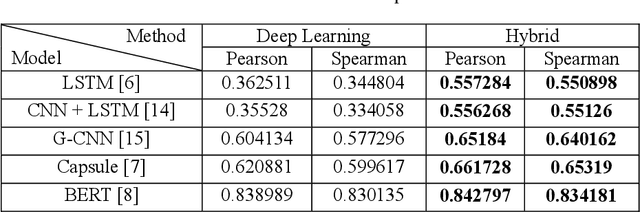
The problem of measuring sentence similarity is an essential issue in the natural language processing (NLP) area. It is necessary to measure the similarity between sentences accurately. There are many approaches to measuring sentence similarity. Deep learning methodology shows a state-of-the-art performance in many natural language processing fields and is used a lot in sentence similarity measurement methods. However, in the natural language processing field, considering the structure of the sentence or the word structure that makes up the sentence is also important. In this study, we propose a methodology combined with both deep learning methodology and a method considering lexical relationships. Our evaluation metric is the Pearson correlation coefficient and Spearman correlation coefficient. As a result, the proposed method outperforms the current approaches on a KorSTS standard benchmark Korean dataset. Moreover, it performs a maximum of 65% increase than only using deep learning methodology. Experiments show that our proposed method generally results in better performance than those with only a deep learning model.