 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaSAB: The variable size adaptive information bottleneck for disentanglement on speech and singing voice
Paper and Code
Oct 05, 2023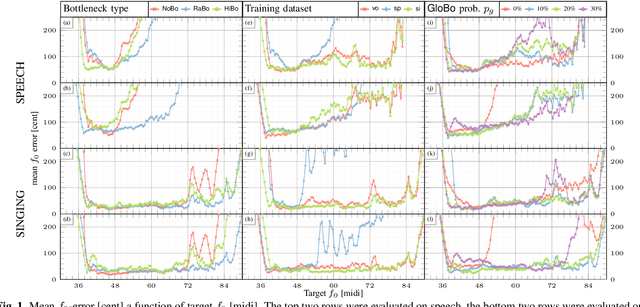
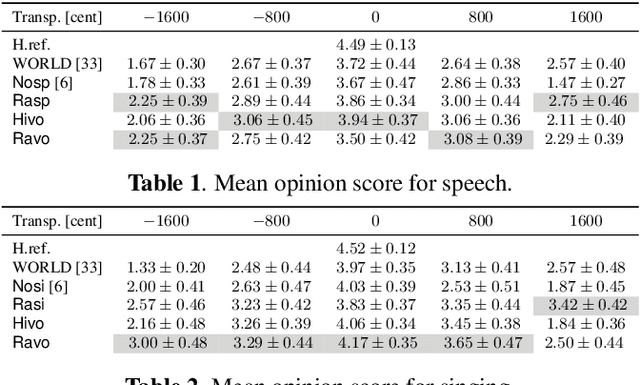
The information bottleneck auto-encoder is a tool for disentanglement commonly used for voice transformation. The successful disentanglement relies on the right choice of bottleneck size. Previous bottleneck auto-encoders created the bottleneck by the dimension of the latent space or through vector quantization and had no means to change the bottleneck size of a specific model. As the bottleneck removes information from the disentangled representation, the choice of bottleneck size is a trade-off between disentanglement and synthesis quality. We propose to build the information bottleneck using dropout which allows us to change the bottleneck through the dropout rate and investigate adapting the bottleneck size depending on the context. We experimentally explore into using the adaptive bottleneck for pitch transformation and demonstrate that the adaptive bottleneck leads to improved disentanglement of the F0 parameter for both, speech and singing voice leading to improved synthesis quality. Using the variable bottleneck size, we were able to achieve disentanglement for singing voice including extremely high pitches and create a universal voice model, that works on both speech and singing voice with improved synthesis quality.