 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021
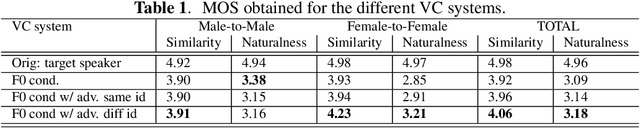
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.
Beyond Voice Identity Conversion: Manipulating Voice Attributes by Adversarial Learning of Structured Disentangled Representations
Jul 27, 2021

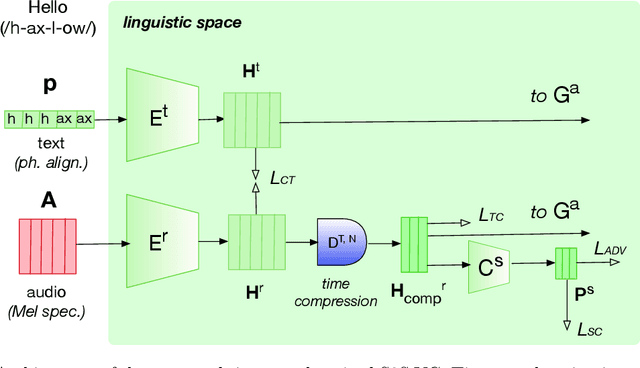
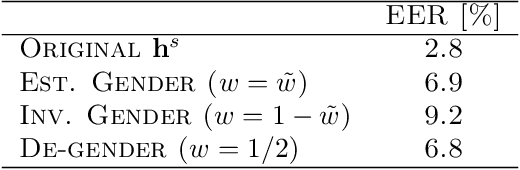
Voice conversion (VC) consists of digitally altering the voice of an individual to manipulate part of its content, primarily its identity, while maintaining the rest unchanged. Research in neural VC has accomplished considerable breakthroughs with the capacity to falsify a voice identity using a small amount of data with a highly realistic rendering. This paper goes beyond voice identity and presents a neural architecture that allows the manipulation of voice attributes (e.g., gender and age). Leveraging the latest advances on adversarial learning of structured speech representation, a novel structured neural network is proposed in which multiple auto-encoders are used to encode speech as a set of idealistically independent linguistic and extra-linguistic representations, which are learned adversariarly and can be manipulated during VC. Moreover, the proposed architecture is time-synchronized so that the original voice timing is preserved during conversion which allows lip-sync applications. Applied to voice gender conversion on the real-world VCTK dataset, our proposed architecture can learn successfully gender-independent representation and convert the voice gender with a very high efficiency and naturalness.