 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and transformations of intensity in singing voice
Paper and Code
Apr 08, 2022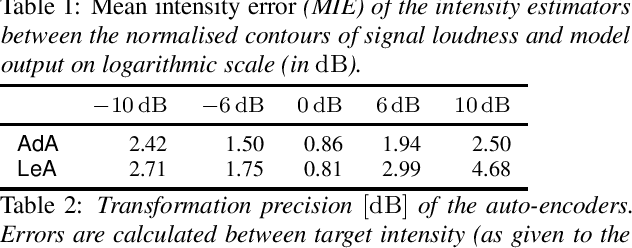

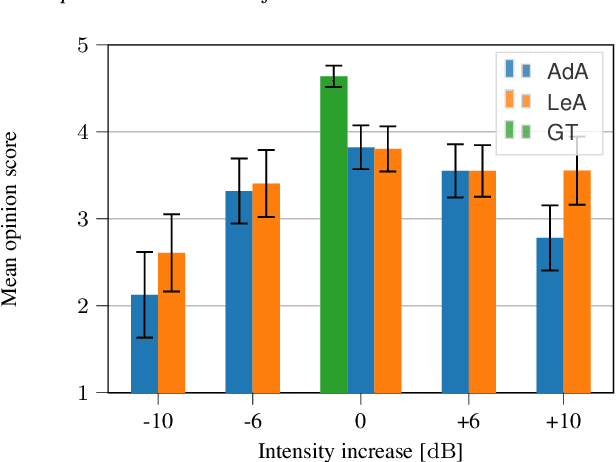

In this paper we introduce a neural auto-encoder that transforms the voice intensity in recordings of singing voice. Since most recordings of singing voice are not annotated with voice intensity we propose a means to estimate the relative voice intensity from the signal's timbre using a neural intensity estimator. Two methods to overcome the unknown recording factor that relates voice intensity to recorded signal power are given: The unknown recording factor can either be learned alongside the weights of the intensity estimator, or a special loss function based on the scalar product can be used to only match the intensity contour of the recorded signal's power. The intensity models are used to condition a previously introduced bottleneck auto-encoder that disentangles its input, the mel-spectrogram, from the intensity. We evaluate the intensity models by their consistency and by their fitness to provide useful information to the auto-encoder. A perceptive test is carried out that evaluates the perceived intensity change in transformed recordings and the synthesis quality. The perceptive test confirms that changing the conditional input changes the perceived intensity accordingly thus suggesting that the proposed intensity models encode information about the voice intensity.