 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Decoding with Visual Entities for Zero-Shot Image Captioning
Paper and Code
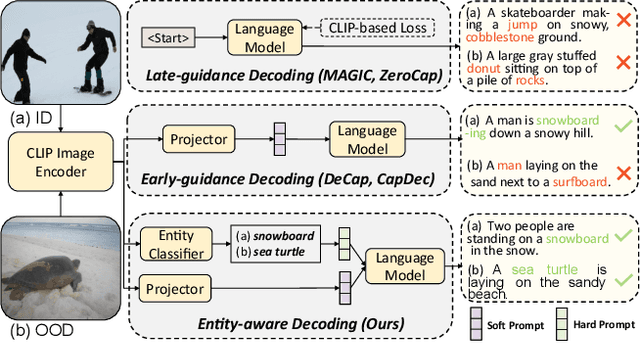
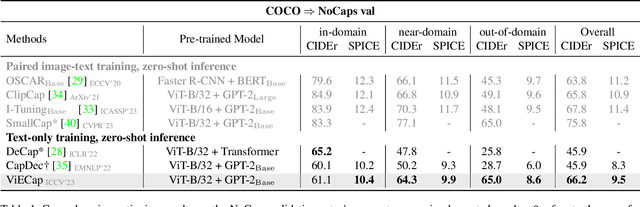
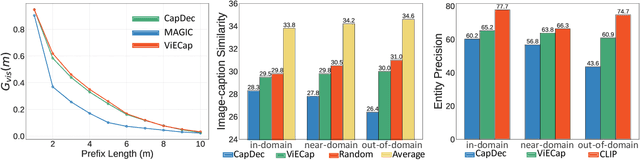
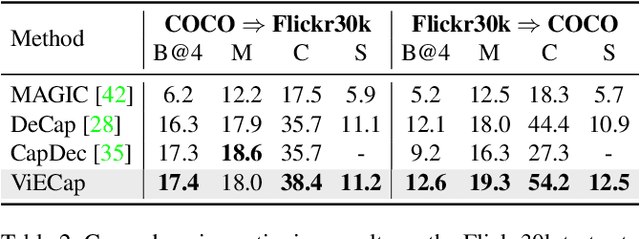
Image-to-text generation aims to describe images using natural language. Recently, zero-shot image captioning based on pre-trained vision-language models (VLMs) and large language models (LLMs) has made significant progress. However, we have observed and empirically demonstrated that these methods are susceptible to modality bias induced by LLMs and tend to generate descriptions containing objects (entities) that do not actually exist in the image but frequently appear during training (i.e., object hallucination). In this paper, we propose ViECap, a transferable decoding model that leverages entity-aware decoding to generate descriptions in both seen and unseen scenarios. ViECap incorporates entity-aware hard prompts to guide LLMs' attention toward the visual entities present in the image, enabling coherent caption generation across diverse scenes. With entity-aware hard prompts, ViECap is capable of maintaining performance when transferring from in-domain to out-of-domain scenarios. Extensive experiments demonstrate that ViECap sets a new state-of-the-art cross-domain (transferable) captioning and performs competitively in-domain captioning compared to previous VLMs-based zero-shot methods. Our code is available at: https://github.com/FeiElysia/ViECap