 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coarse to Fine: Efficient Training for Audio Spectrogram Transformers
Paper and Code
Jan 16, 2024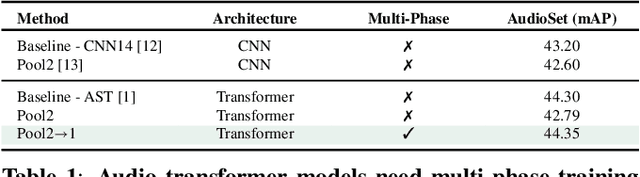
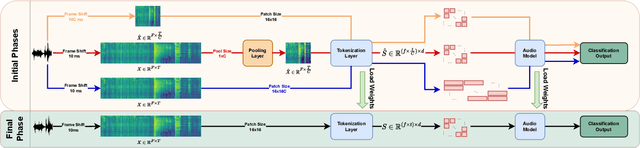
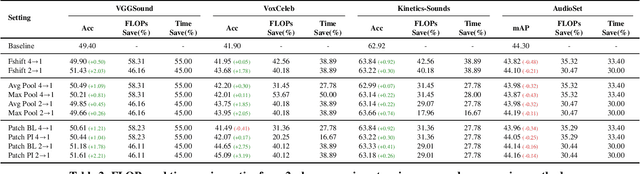
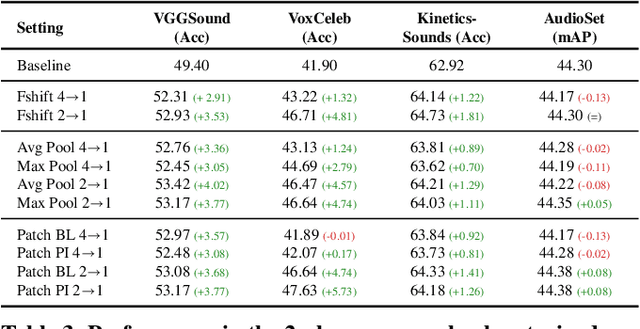
Transformers have become central to recent advances in audio classification. However, training an audio spectrogram transformer, e.g. AST, from scratch can be resource and time-intensive. Furthermore, the complexity of transformers heavily depends on the input audio spectrogram size. In this work, we aim to optimize AST training by linking to the resolution in the time-axis. We introduce multi-phase training of audio spectrogram transformers by connecting the seminal idea of coarse-to-fine with transformer models. To achieve this, we propose a set of methods for temporal compression. By employing one of these methods, the transformer model learns from lower-resolution (coarse) data in the initial phases, and then is fine-tuned with high-resolution data later in a curriculum learning strategy. Experimental results demonstrate that the proposed training mechanism for AST leads to improved (or on-par) performance with faster convergence, i.e. requiring fewer computational resources and less time. This approach is also generalizable to other AST-based methods regardless of their learning paradigms.