 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Generative Bias for Visual Question Answering
Aug 02, 2022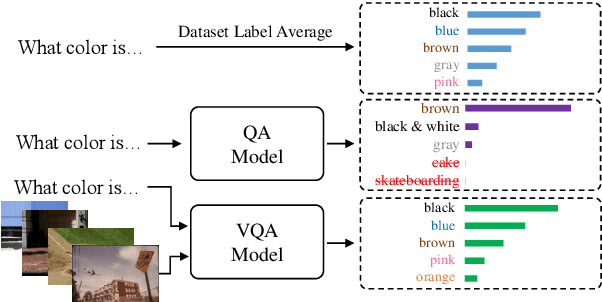
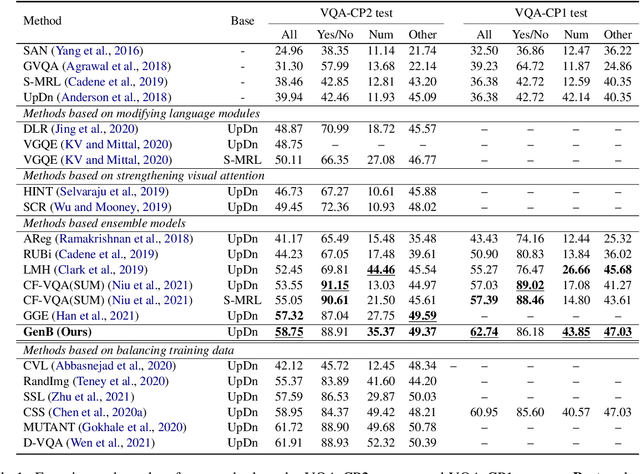

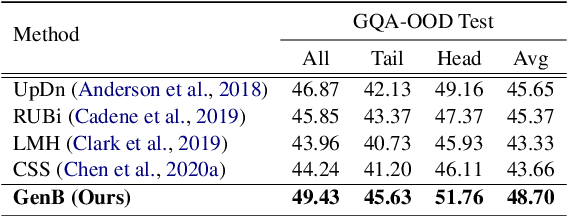
The task of Visual Question Answering (VQA) is known to be plagued by the issue of VQA models exploiting biases within the dataset to make its final prediction. Many previous ensemble based debiasing methods have been proposed where an additional model is purposefully trained to be biased in order to aid in training a robust target model. However, these methods compute the bias for a model from the label statistics of the training data or directly from single modal branches. In contrast, in this work, in order to better learn the bias a target VQA model suffers from, we propose a generative method to train the bias model \emph{directly from the target model}, called GenB. In particular, GenB employs a generative network to learn the bias through a combination of the adversarial objective and knowledge distillation. We then debias our target model with GenB as a bias model, and show through extensive experiments the effects of our method on various VQA bias datasets including VQA-CP2, VQA-CP1, GQA-OOD, and VQA-CE.
LabOR: Labeling Only if Required for Domain Adaptive Semantic Segmentation
Aug 12, 2021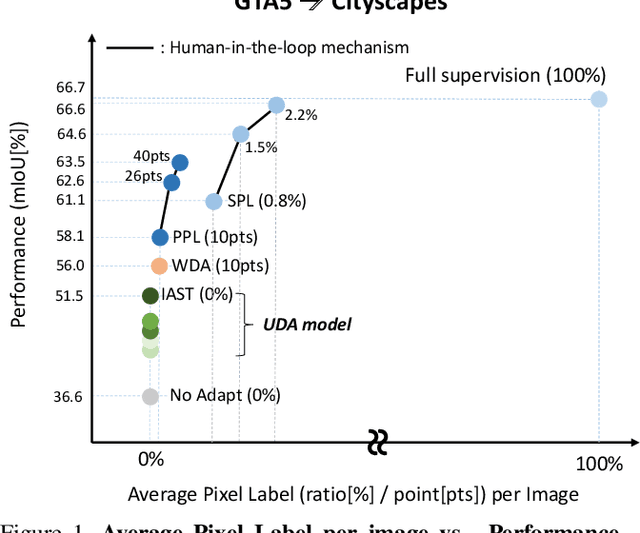
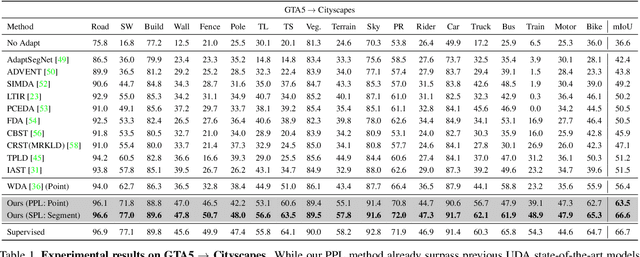
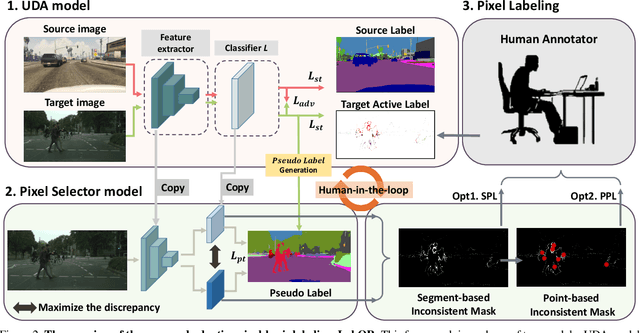
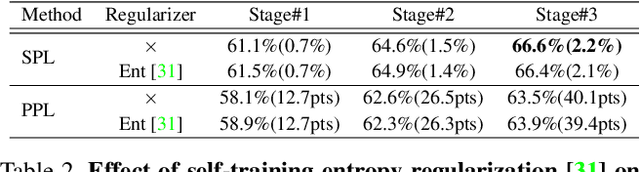
Unsupervised Domain Adaptation (UDA) for semantic segmentation has been actively studied to mitigate the domain gap between label-rich source data and unlabeled target data. Despite these efforts, UDA still has a long way to go to reach the fully supervised performance. To this end, we propose a Labeling Only if Required strategy, LabOR, where we introduce a human-in-the-loop approach to adaptively give scarce labels to points that a UDA model is uncertain about. In order to find the uncertain points, we generate an inconsistency mask using the proposed adaptive pixel selector and we label these segment-based regions to achieve near supervised performance with only a small fraction (about 2.2%) ground truth points, which we call "Segment based Pixel-Labeling (SPL)". To further reduce the efforts of the human annotator, we also propose "Point-based Pixel-Labeling (PPL)", which finds the most representative points for labeling within the generated inconsistency mask. This reduces efforts from 2.2% segment label to 40 points label while minimizing performance degradation. Through extensive experimentation, we show the advantages of this new framework for domain adaptive semantic segmentation while minimizing human labor costs.