 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision
Paper and Code
Oct 06, 2021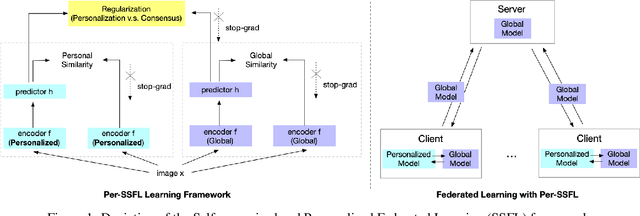

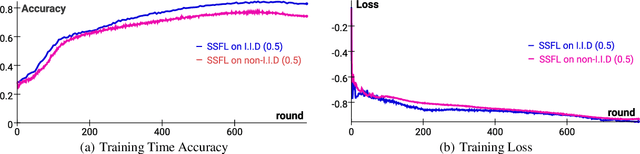
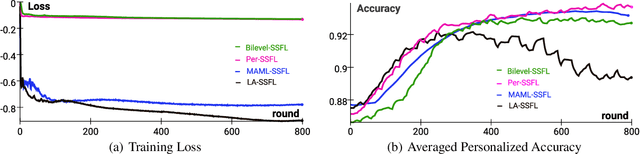
Federated Learning (FL) is transforming the ML training ecosystem from a centralized over-the-cloud setting to distributed training over edge devices in order to strengthen data privacy. An essential but rarely studied challenge in FL is label deficiency at the edge. This problem is even more pronounced in FL compared to centralized training due to the fact that FL users are often reluctant to label their private data. Furthermore, due to the heterogeneous nature of the data at edge devices, it is crucial to develop personalized models. In this paper we propose self-supervised federated learning (SSFL), a unified self-supervised and personalized federated learning framework, and a series of algorithms under this framework which work towards addressing these challenges. First, under the SSFL framework, we demonstrate that the standard FedAvg algorithm is compatible with recent breakthroughs in centralized self-supervised learning such as SimSiam networks. Moreover, to deal with data heterogeneity at the edge devices in this framework, we have innovated a series of algorithms that broaden existing supervised personalization algorithms into the setting of self-supervised learning. We further propose a novel personalized federated self-supervised learning algorithm, Per-SSFL, which balances personalization and consensus by carefully regulating the distance between the local and global representations of data. To provide a comprehensive comparative analysis of all proposed algorithms, we also develop a distributed training system and related evaluation protocol for SSFL. Our findings show that the gap of evaluation accuracy between supervised learning and unsupervised learning in FL is both small and reasonable. The performance comparison indicates the representation regularization-based personalization method is able to outperform other variants.