 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
Paper and Code

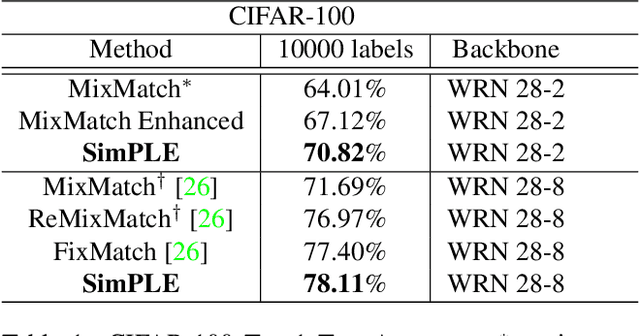
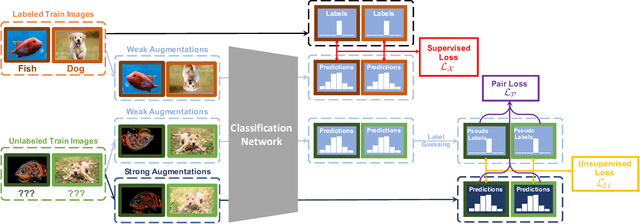
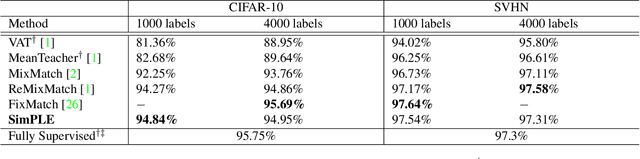
A common classification task situation is where one has a large amount of data available for training, but only a small portion is annotated with class labels. The goal of semi-supervised training, in this context, is to improve classification accuracy by leverage information not only from labeled data but also from a large amount of unlabeled data. Recent works have developed significant improvements by exploring the consistency constrain between differently augmented labeled and unlabeled data. Following this path, we propose a novel unsupervised objective that focuses on the less studied relationship between the high confidence unlabeled data that are similar to each other. The new proposed Pair Loss minimizes the statistical distance between high confidence pseudo labels with similarity above a certain threshold. Combining the Pair Loss with the techniques developed by the MixMatch family, our proposed SimPLE algorithm shows significant performance gains over previous algorithms on CIFAR-100 and Mini-ImageNet, and is on par with the state-of-the-art methods on CIFAR-10 and SVHN. Furthermore, SimPLE also outperforms the state-of-the-art methods in the transfer learning setting, where models are initialized by the weights pre-trained on ImageNet or DomainNet-Real. The code is available at github.com/zijian-hu/SimPLE.