 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Aggregator for Defending Federated Backdoor Attacks
Paper and Code
Oct 04, 2022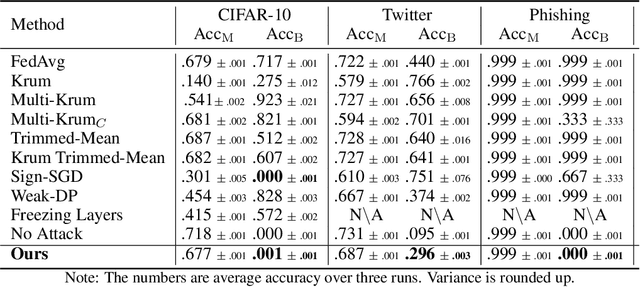



Federated learning is gaining popularity as it enables training of high-utility models across several clients without directly sharing their private data. As a downside, the federated setting makes the model vulnerable to various adversarial attacks in the presence of malicious clients. Specifically, an adversary can perform backdoor attacks to control model predictions via poisoning the training dataset with a trigger. In this work, we propose a mitigation for backdoor attacks in a federated learning setup. Our solution forces the model optimization trajectory to focus on the invariant directions that are generally useful for utility and avoid selecting directions that favor few and possibly malicious clients. Concretely, we consider the sign consistency of the pseudo-gradient (the client update) as an estimation of the invariance. Following this, our approach performs dimension-wise filtering to remove pseudo-gradient elements with low sign consistency. Then, a robust mean estimator eliminates outliers among the remaining dimensions. Our theoretical analysis further shows the necessity of the defense combination and illustrates how our proposed solution defends the federated learning model. Empirical results on three datasets with different modalities and varying number of clients show that our approach mitigates backdoor attacks with a negligible cost on the model utility.