 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Synthetic Audio From Generative Foundation Models Assist Audio Recognition and Speech Modeling?
Paper and Code



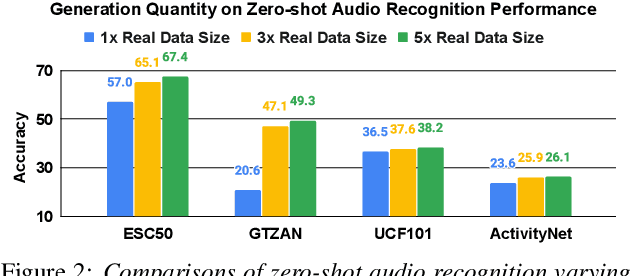
Recent advances in foundation models have enabled audio-generative models that produce high-fidelity sounds associated with music, events, and human actions. Despite the success achieved in modern audio-generative models, the conventional approach to assessing the quality of the audio generation relies heavily on distance metrics like Frechet Audio Distance. In contrast, we aim to evaluate the quality of audio generation by examining the effectiveness of using them as training data. Specifically, we conduct studies to explore the use of synthetic audio for audio recognition. Moreover, we investigate whether synthetic audio can serve as a resource for data augmentation in speech-related modeling. Our comprehensive experiments demonstrate the potential of using synthetic audio for audio recognition and speech-related modeling. Our code is available at https://github.com/usc-sail/SynthAudio.