 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Personality Recognition by Comparing the Predictive Power of Traits, Facets, and Nuances
Feb 05, 2026Personality is a complex, hierarchical construct typically assessed through item-level questionnaires aggregated into broad trait scores. Personality recognition models aim to infer personality traits from different sources of behavioral data. However, reliance on broad trait scores as ground truth, combined with limited training data, poses challenges for generalization, as similar trait scores can manifest through diverse, context dependent behaviors. In this work, we explore the predictive impact of the more granular hierarchical levels of the Big-Five Personality Model, facets and nuances, to enhance personality recognition from audiovisual interaction data. Using the UDIVA v0.5 dataset, we trained a transformer-based model including cross-modal (audiovisual) and cross-subject (dyad-aware) attention mechanisms. Results show that nuance-level models consistently outperform facet and trait-level models, reducing mean squared error by up to 74% across interaction scenarios.
Dyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Sep 20, 2021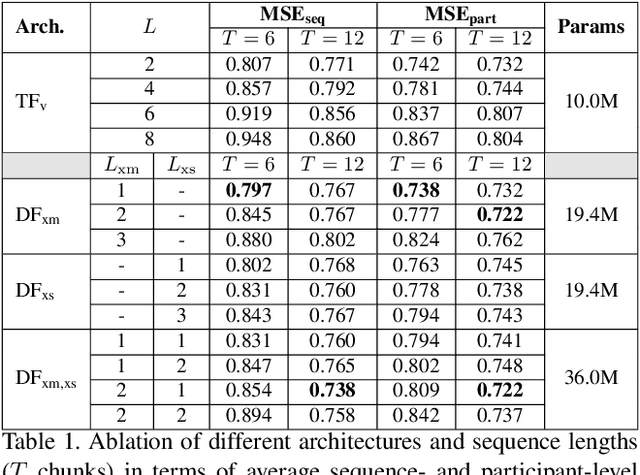
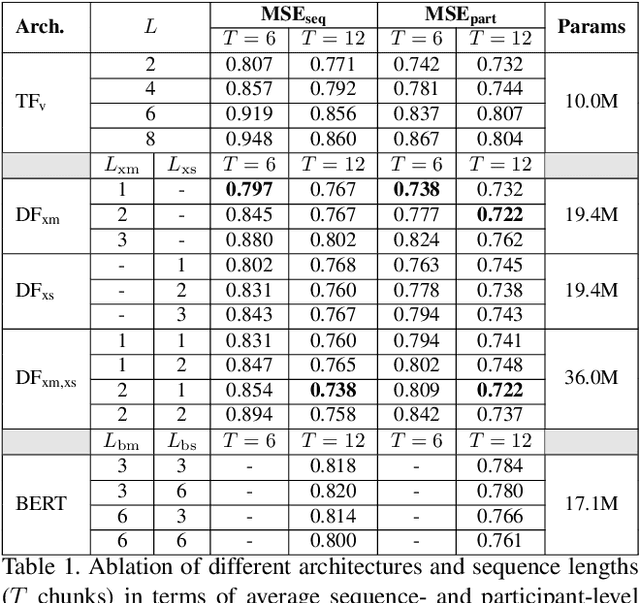
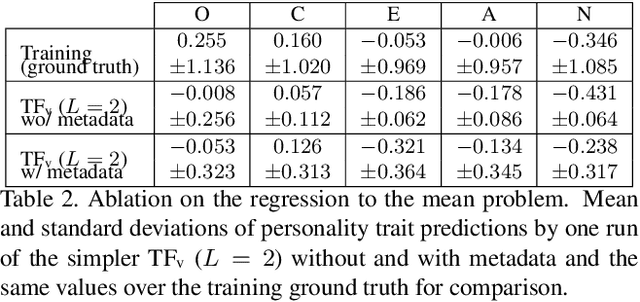
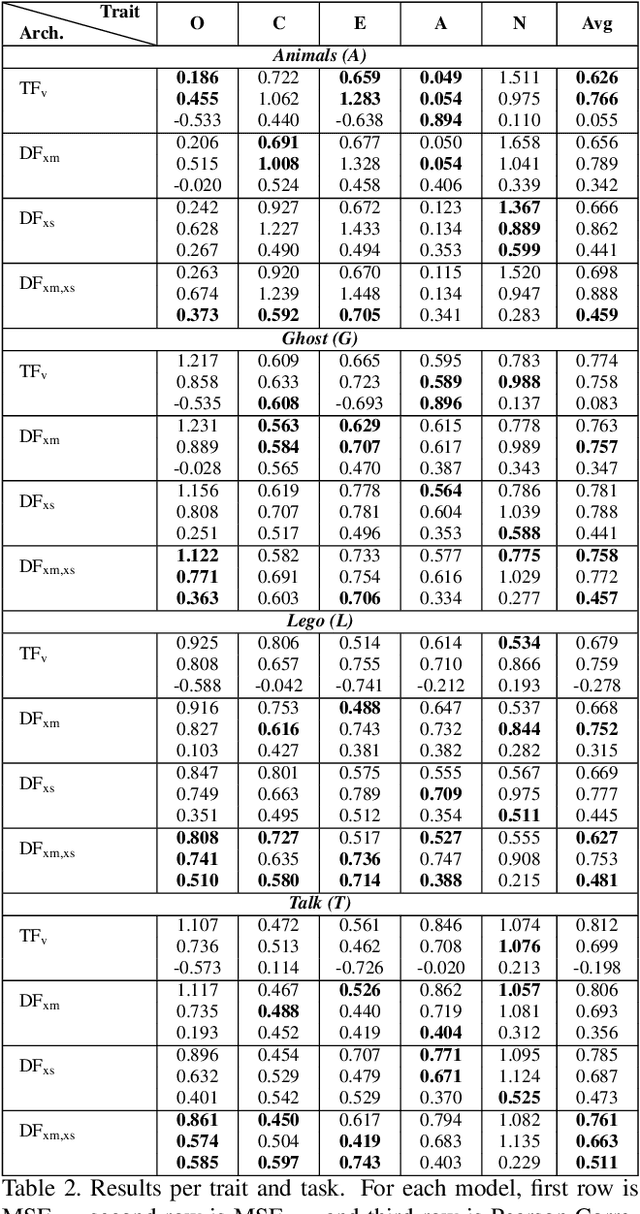
Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for. However, most works on the topic have focused on analyzing the individual, even when applied to interaction scenarios, and for short periods of time. To address these limitations, we present the Dyadformer, a novel multi-modal multi-subject Transformer architecture to model individual and interpersonal features in dyadic interactions using variable time windows, thus allowing the capture of long-term interdependencies. Our proposed cross-subject layer allows the network to explicitly model interactions among subjects through attentional operations. This proof-of-concept approach shows how multi-modality and joint modeling of both interactants for longer periods of time helps to predict individual attributes. With Dyadformer, we improve state-of-the-art self-reported personality inference results on individual subjects on the UDIVA v0.5 dataset.