 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Representation Learning With Path Integral Clustering For Speaker Diarization
Paper and Code
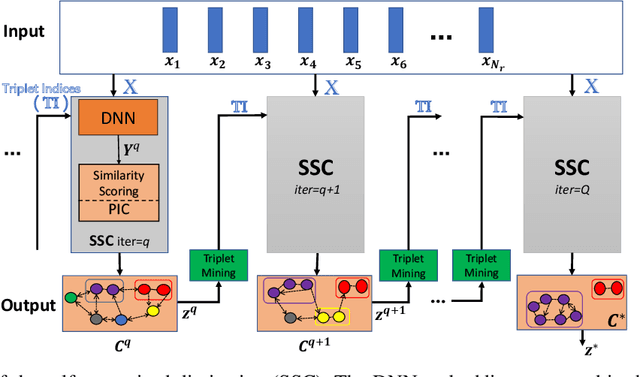
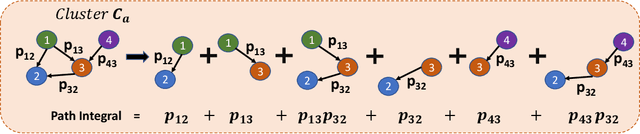
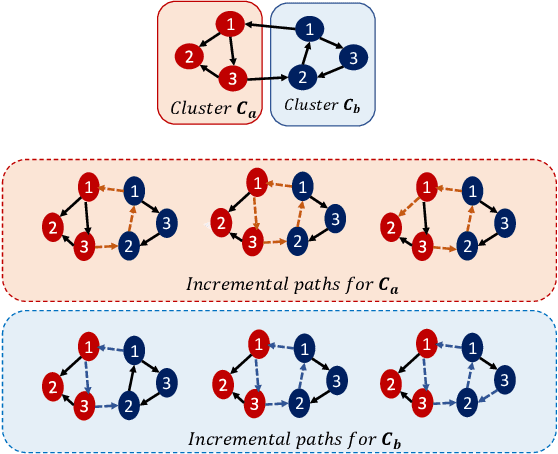
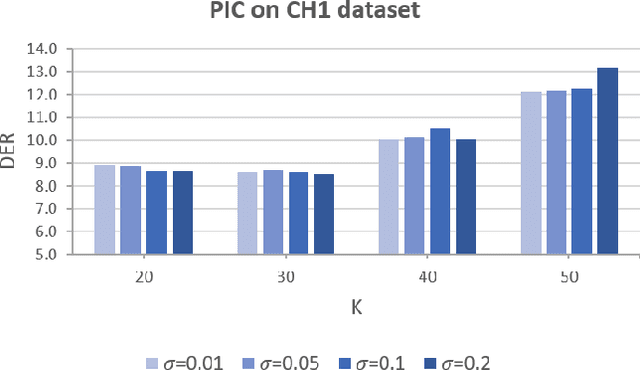
Automatic speaker diarization techniques typically involve a two-stage processing approach where audio segments of fixed duration are converted to vector representations in the first stage. This is followed by an unsupervised clustering of the representations in the second stage. In most of the prior approaches, these two stages are performed in an isolated manner with independent optimization steps. In this paper, we propose a representation learning and clustering algorithm that can be iteratively performed for improved speaker diarization. The representation learning is based on principles of self-supervised learning while the clustering algorithm is a graph structural method based on path integral clustering (PIC). The representation learning step uses the cluster targets from PIC and the clustering step is performed on embeddings learned from the self-supervised deep model. This iterative approach is referred to as self-supervised clustering (SSC). The diarization experiments are performed on CALLHOME and AMI meeting datasets. In these experiments, we show that the SSC algorithm improves significantly over the baseline system (relative improvements of 13% and 59% on CALLHOME and AMI datasets respectively in terms of diarization error rate (DER)). In addition, the DER results reported in this work improve over several other recent approaches for speaker diarization.