 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspAct: Enhancing LLM Situated Collaboration Skills through Perspective Taking and Active Vision
Nov 11, 2025Recent advances in Large Language Models (LLMs) and multimodal foundation models have significantly broadened their application in robotics and collaborative systems. However, effective multi-agent interaction necessitates robust perspective-taking capabilities, enabling models to interpret both physical and epistemic viewpoints. Current training paradigms often neglect these interactive contexts, resulting in challenges when models must reason about the subjectivity of individual perspectives or navigate environments with multiple observers. This study evaluates whether explicitly incorporating diverse points of view using the ReAct framework, an approach that integrates reasoning and acting, can enhance an LLM's ability to understand and ground the demands of other agents. We extend the classic Director task by introducing active visual exploration across a suite of seven scenarios of increasing perspective-taking complexity. These scenarios are designed to challenge the agent's capacity to resolve referential ambiguity based on visual access and interaction, under varying state representations and prompting strategies, including ReAct-style reasoning. Our results demonstrate that explicit perspective cues, combined with active exploration strategies, significantly improve the model's interpretative accuracy and collaborative effectiveness. These findings highlight the potential of integrating active perception with perspective-taking mechanisms in advancing LLMs' application in robotics and multi-agent systems, setting a foundation for future research into adaptive and context-aware AI systems.
SCOOP: A Framework for Proactive Collaboration and Social Continual Learning through Natural Language Interaction andCausal Reasoning
Mar 13, 2025Multimodal information-gathering settings, where users collaborate with AI in dynamic environments, are increasingly common. These involve complex processes with textual and multimodal interactions, often requiring additional structural information via cost-incurring requests. AI helpers lack access to users' true goals, beliefs, and preferences and struggle to integrate diverse information effectively. We propose a social continual learning framework for causal knowledge acquisition and collaborative decision-making. It focuses on autonomous agents learning through dialogues, question-asking, and interaction in open, partially observable environments. A key component is a natural language oracle that answers the agent's queries about environmental mechanisms and states, refining causal understanding while balancing exploration or learning, and exploitation or knowledge use. Evaluation tasks inspired by developmental psychology emphasize causal reasoning and question-asking skills. They complement benchmarks by assessing the agent's ability to identify knowledge gaps, generate meaningful queries, and incrementally update reasoning. The framework also evaluates how knowledge acquisition costs are amortized across tasks within the same environment. We propose two architectures: 1) a system combining Large Language Models (LLMs) with the ReAct framework and question-generation, and 2) an advanced system with a causal world model, symbolic, graph-based, or subsymbolic, for reasoning and decision-making. The latter builds a causal knowledge graph for efficient inference and adaptability under constraints. Challenges include integrating causal reasoning into ReAct and optimizing exploration and question-asking in error-prone scenarios. Beyond applications, this framework models developmental processes combining causal reasoning, question generation, and social learning.
One to rule them all: natural language to bind communication, perception and action
Nov 22, 2024In recent years, research in the area of human-robot interaction has focused on developing robots capable of understanding complex human instructions and performing tasks in dynamic and diverse environments. These systems have a wide range of applications, from personal assistance to industrial robotics, emphasizing the importance of robots interacting flexibly, naturally and safely with humans. This paper presents an advanced architecture for robotic action planning that integrates communication, perception, and planning with Large Language Models (LLMs). Our system is designed to translate commands expressed in natural language into executable robot actions, incorporating environmental information and dynamically updating plans based on real-time feedback. The Planner Module is the core of the system where LLMs embedded in a modified ReAct framework are employed to interpret and carry out user commands. By leveraging their extensive pre-trained knowledge, LLMs can effectively process user requests without the need to introduce new knowledge on the changing environment. The modified ReAct framework further enhances the execution space by providing real-time environmental perception and the outcomes of physical actions. By combining robust and dynamic semantic map representations as graphs with control components and failure explanations, this architecture enhances a robot adaptability, task execution, and seamless collaboration with human users in shared and dynamic environments. Through the integration of continuous feedback loops with the environment the system can dynamically adjusts the plan to accommodate unexpected changes, optimizing the robot ability to perform tasks. Using a dataset of previous experience is possible to provide detailed feedback about the failure. Updating the LLMs context of the next iteration with suggestion on how to overcame the issue.
Time is on my sight: scene graph filtering for dynamic environment perception in an LLM-driven robot
Nov 22, 2024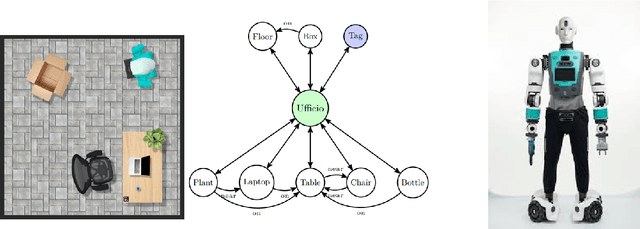

Robots are increasingly being used in dynamic environments like workplaces, hospitals, and homes. As a result, interactions with robots must be simple and intuitive, with robots perception adapting efficiently to human-induced changes. This paper presents a robot control architecture that addresses key challenges in human-robot interaction, with a particular focus on the dynamic creation and continuous update of the robot state representation. The architecture uses Large Language Models to integrate diverse information sources, including natural language commands, robotic skills representation, real-time dynamic semantic mapping of the perceived scene. This enables flexible and adaptive robotic behavior in complex, dynamic environments. Traditional robotic systems often rely on static, pre-programmed instructions and settings, limiting their adaptability to dynamic environments and real-time collaboration. In contrast, this architecture uses LLMs to interpret complex, high-level instructions and generate actionable plans that enhance human-robot collaboration. At its core, the system Perception Module generates and continuously updates a semantic scene graph using RGB-D sensor data, providing a detailed and structured representation of the environment. A particle filter is employed to ensure accurate object localization in dynamic, real-world settings. The Planner Module leverages this up-to-date semantic map to break down high-level tasks into sub-tasks and link them to robotic skills such as navigation, object manipulation (e.g., PICK and PLACE), and movement (e.g., GOTO). By combining real-time perception, state tracking, and LLM-driven communication and task planning, the architecture enhances adaptability, task efficiency, and human-robot collaboration in dynamic environments.